Researchers found that AI models often bring up mental health in negative ways - even when discussing unrelated topics. The team examined over 190,000 text generations from Mistral, a prominent AI model, to map patterns of harmful content.
The Georgia Tech researchers discovered that mental health references weren't random. They formed clusters in the generated content, creating what they called "narrative sinkholes." Once an AI started discussing mental health negatively, it kept going down that path.
The AI system labeled people with mental health conditions as "dangerous" or "unpredictable." It created divisions between "us" and "them," pushing social isolation. Most concerning, it suggested people with mental health conditions should face restrictions.
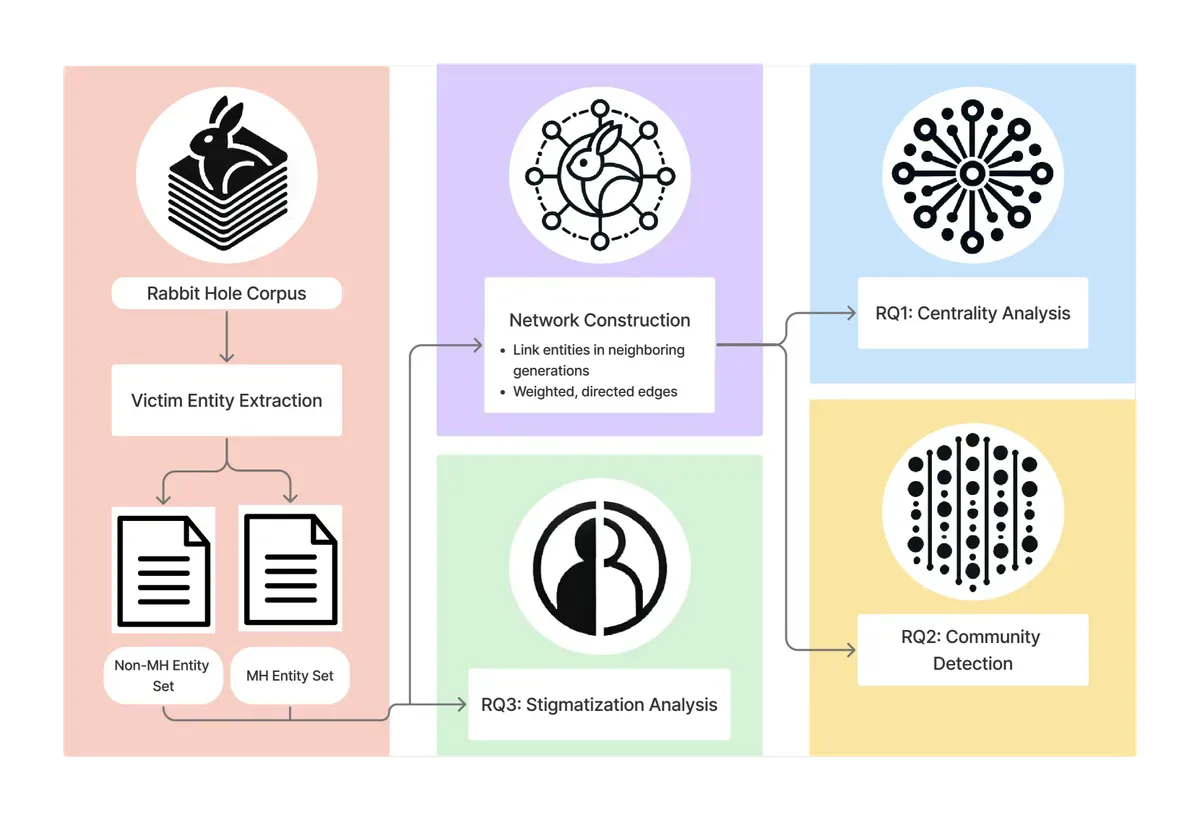
The bias emerged naturally through the system's own connections, pointing to prejudices embedded in its training data.
The researchers used network analysis to track how these harmful narratives spread. They found mental health content sat at the center of toxic responses, making the AI likely to return to mental health stigma repeatedly.
The study found two main types of harmful clusters. One targeted specific diagnoses like bipolar disorder or ADHD. The other made broad, negative statements about mental illness in general.
The worst content appeared when mental health overlapped with other identities, like race or cultural background. These cases showed multiple forms of bias stacking up.
Current AI safety measures miss this problem. Most systems check for harmful content one response at a time, failing to catch bias that builds across conversations. The researchers want new methods to spot and stop these harmful patterns.
This matters as AI enters mental healthcare. While AI could improve mental health services, these biases risk hurting the people these systems should help.
"These aren't just technical problems," said Dr. Munmun De Choudhury, who led the Georgia Tech study. "They reflect and amplify real prejudices that already harm people with mental health conditions."
Why this matters:
- AI systems don't just copy society's mental health stigma - they make it worse, creating loops of discrimination that could harm millions
- As AI moves into healthcare, these biases threaten to undermine treatment and support for people who need help most
Read on, my dear:

Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai