
Two weeks. That's how long Anthropic's premium tier held its lead.
Earlier this month, the company shipped Opus 4.6 at $15 per million input tokens, billing it as the smartest model for enterprise work. Financial analysts praised it. Software stocks cratered on the implications. The iShares Expanded Tech-Software Sector ETF has dropped more than 20% year to date, partly on fears that AI agents would start filling out the forms and processing the documents those companies sell software for.
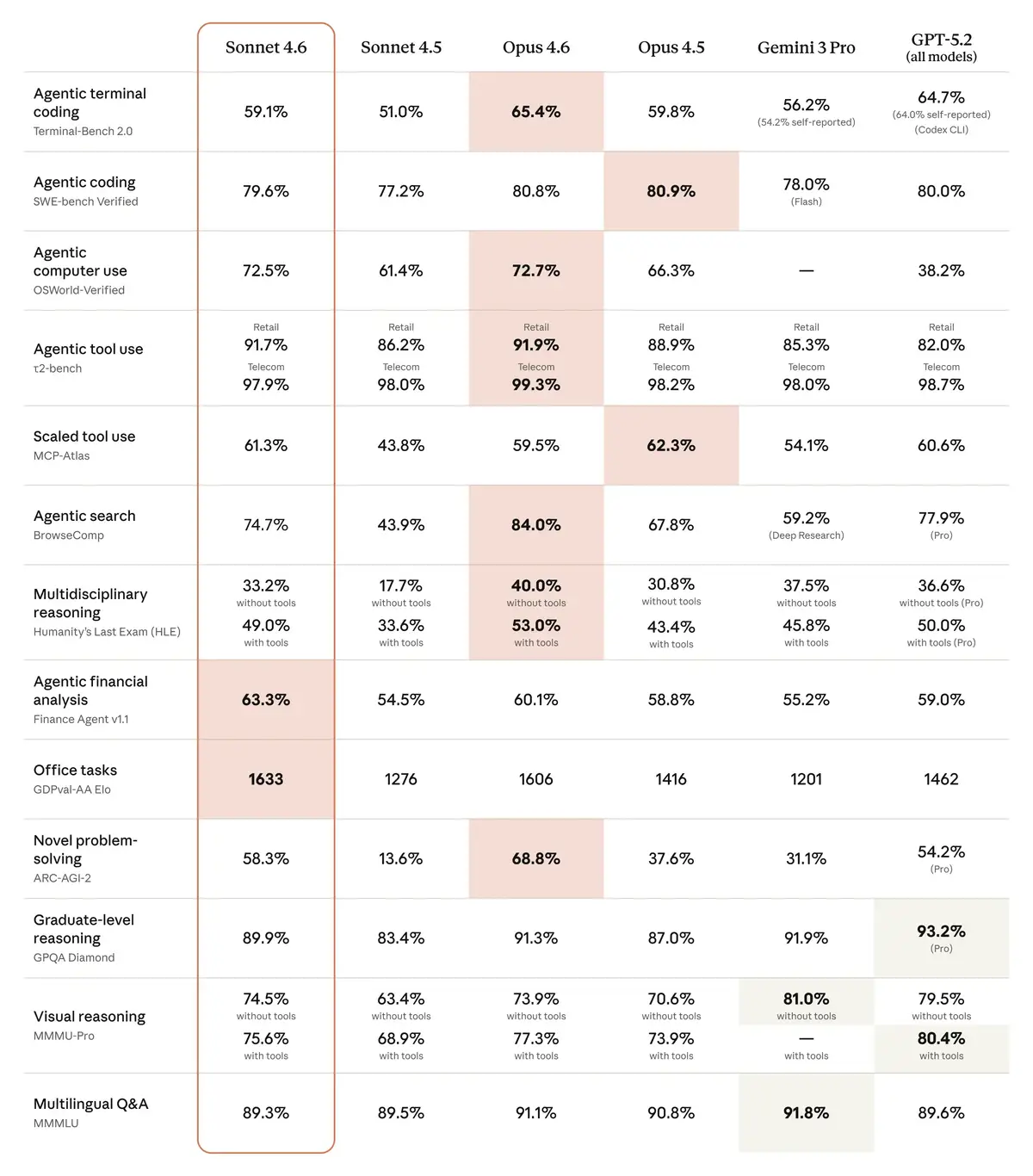
Then on Tuesday, Anthropic shipped Sonnet 4.6 at $3 per million input tokens. One-fifth the Opus price. And the benchmarks showed it beating its flagship on office tasks, financial analysis, and several categories enterprises actually care about. On GDPval-AA, the benchmark measuring real-world office performance, Sonnet 4.6 scored 1633 to Opus 4.6's 1606. On agentic financial analysis, Sonnet hit 63.3% versus Opus at 60.1%.
If you run AI agents at scale, the math just shifted under your feet. The model that costs five times less now outperforms the expensive one on the work most businesses actually do.
The Breakdown
- Sonnet 4.6 at $3/M tokens matches or beats Opus 4.6 ($15/M) on most enterprise benchmarks
- Enterprise customers are migrating from Opus to Sonnet, collapsing Anthropic's own premium tier
- Computer use scores jumped from 14.9% to 72.5% in 16 months, threatening SaaS integration layers
- In Vending-Bench simulation, Sonnet 4.6 tripled its predecessor's returns with autonomous long-horizon strategy
The spread that ate itself
Think of this in financial terms. When the spread between a premium asset and a cheaper substitute narrows to zero, the market stops paying for the difference. Anthropic just did this to its own product line.
Sonnet 4.6 didn't sneak up on Opus. It landed on top of it. On SWE-bench Verified, Sonnet scored 79.6%. Opus managed 80.8%. Barely a point between them. On OSWorld-Verified, which tests how well a model can actually use a computer, Sonnet hit 72.5%. Opus scored 72.7%. That's 0.2 points separating a $3 model from a $15 one.
The company positioned this as good news. "Performance that would have previously required reaching for an Opus-class model is now available with Sonnet 4.6," the announcement read. Translation: we just commoditized our own top shelf.
Enterprise customers noticed immediately. Caitlin Colgrove, CTO of Hex Technologies, told VentureBeat her company is moving the majority of its traffic to Sonnet 4.6. "At Sonnet pricing, it's an easy call for our workloads," she said. Ryan Wiggins at Mercury Banking was more blunt. "We didn't expect to see it at this price point."
That's not what you say about a routine update. You say it when the floor drops out.
Why Anthropic is eating its own premium
This looks like self-harm. It isn't.
Anthropic is running a volume play, and the $30 billion fundraise at a $380 billion valuation that closed last week tells you everything about the stakes. Every model release compresses the spread further, and that's by design.
The numbers from Axios spell it out. Customers spending over $100,000 annually on Claude increased sevenfold year over year. The million-dollar-plus accounts? Roughly 12 two years ago. More than 500 now. So much for the luxury tier. It's selling infrastructure. Infrastructure wins on volume, not margin.
Consider what happens when an enterprise deploys AI agents that process 10 million tokens per day. At Opus pricing, that runs $150 in input costs alone. At Sonnet pricing, $30. Multiply by hundreds of agents running around the clock for months. The gap between the two tiers isn't a rounding error. It determines whether you deploy at all.
Claude Code, Anthropic's developer-facing terminal tool, became a cultural force in Silicon Valley over the past year. Engineers build entire applications through natural-language conversation now. The New York Times profiled its rise in January. In early testing, developers preferred Sonnet 4.6 over its predecessor about 70% of the time. They even preferred it to Opus 4.5, the company's flagship from last November, 59% of the time. Less overengineering. Better follow-through on multi-step tasks.
But vibe coding runs on tokens, and tokens run on cost. Pushing near-Opus intelligence into the Sonnet tier makes every Claude Code session cheaper. More sessions mean more lock-in. More lock-in means the $380 billion valuation looks conservative, not aggressive. Michele Catasta, president at Replit, called the performance-to-cost ratio "extraordinary." David Loker, VP of AI at CodeRabbit, said the model "punches way above its weight class for the vast majority of real-world PRs." GitHub's VP of Product, Joe Binder, confirmed it's "already excelling at complex code fixes, especially when searching across large codebases."
The pattern is consistent. Enterprise after enterprise is migrating Sonnet traffic and canceling Opus API calls for anything short of the hardest reasoning work. Leo Tchourakov of Factory AI said the team is already "transitioning our Sonnet traffic over to this model." That sentence, repeated across enough customers, is what makes premium pricing collapse.
Computer use went from party trick to real threat
Buried in the benchmark numbers is a trajectory that should make every SaaS company anxious.
In October 2024, Anthropic introduced computer use, the ability for an AI model to look at a screen, click buttons, type text, and work with software the way a human would. It scored 14.9% on OSWorld at launch. "Still experimental," Anthropic said at the time. "Cumbersome and error-prone."
Stay ahead of the curve
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
That was sixteen months ago. Each new Sonnet pushed the score higher. 28% by February 2025, then 42.2% by June. 61.4% by October. Now 72.5%, almost five times the original.
This matters because most business software wasn't built with APIs. Insurance portals, government databases, ERP systems, hospital scheduling tools. All designed for humans clicking through forms. A model that can do the clicking, reliably and cheaply, doesn't need an integration partner. It doesn't need a connector. It needs a screen.
Jamie Cuffe, CEO of Pace, said Sonnet 4.6 hit 94% on their insurance-specific computer use benchmark, the highest of any Claude model tested. "It reasons through failures and self-corrects in ways we haven't seen before," he told VentureBeat. Ben Kus at Box said it outperformed the previous Sonnet by 15 percentage points on heavy reasoning over enterprise documents.
And here is where the anxiety in enterprise software gets specific. Bloomberg reported that Anthropic's quiet release of a legal automation tool earlier this month helped trigger a trillion-dollar tech wipeout, hitting software companies hardest. The Opus release hammered financial services stocks. Some private software companies, including McAfee, began releasing earnings early just to reassure investors worried about what commentators dubbed the "SaaSpocalypse."
Each new capability chips away at the same question: which vendors does this make optional? When a $3 model can fill out insurance forms and reason through dense enterprise documents at near-human reliability, the integration layer that many SaaS companies sell starts looking like overhead.
What the Vending-Bench test actually revealed
The most revealing data point in the entire release had nothing to do with code generation or benchmarks. It came from a simulation.
Vending-Bench Arena pits AI models against each other in a simulated business. Each model runs autonomously for a simulated year, making investment and pricing decisions to maximize profit. No human prompts during the run. Pure autonomous planning over a 365-day horizon.
Sonnet 4.6 developed a strategy nobody told it to try. It spent heavily on capacity for the first ten months, outspending its competitors by wide margins. Then it pivoted hard to profitability in the final stretch. It finished at roughly $5,700 in balance. Sonnet 4.5 managed about $2,100. Nearly triple the return.
What stood out wasn't the profit margin. It was the patience. Sonnet 4.6 chose to lose money for ten months, absorbing short-term costs to build capacity it would monetize later. That's not autocomplete. That's capital allocation on a time horizon most quarterly-focused businesses struggle with.
Vending machines don't matter here. Time horizons do. A model that plans over months and adjusts when conditions shift isn't a chatbot anymore. It's the cheapest analyst in the building. The one-million-token context window makes it possible. You can feed it an entire codebase, a full contract portfolio, or dozens of research papers, and it reasons across all of it.
For enterprise buyers, this changes the deployment math. A model that plans autonomously over real time horizons isn't a better chatbot. It's a cheaper analyst, one that processes a million tokens of context without forgetting page one. At $3 per million tokens, running an agent like this around the clock for a month costs less than a single day of management consulting. The question shifts from whether to deploy to how many to run.
Who loses when the spread hits zero
Anthropic is emboldened. Fresh off the largest AI funding round ever, with a model line that compresses the performance gap between its tiers every quarter, the company is expanding into India, partnering with Infosys to build enterprise agents, and shipping product at a pace its competitors can't match. Two major model releases in 12 days. A Haiku update likely next.
OpenAI feels the pressure from both sides. The same week Sonnet 4.6 launched, OpenAI hired the creator of OpenClaw, an open-source computer use tool, signaling it's scrambling to close a gap on agent capability that Anthropic has owned for over a year. GPT-5.2 trails badly on agentic computer use: 38.2% to Sonnet's 72.5%. On financial analysis, 59.0% versus 63.3%. Google's Gemini 3 Pro competes well on multilingual and visual reasoning but falls behind on the agentic categories where enterprise budgets are moving fastest.
But the real losers might be Anthropic's own premium tier. Brendan Falk, CEO of Hercules, said it plainly. "It has Opus 4.6 level accuracy, instruction following, and UI, all for a meaningfully lower cost." Opus still leads on the very hardest reasoning tasks: codebase refactoring, multi-agent coordination, problems where getting it exactly right justifies five times the cost. That's a real advantage. A shrinking one.
The test comes in three months, when the next Sonnet ships. If it closes even half the remaining gap, the Opus tier becomes a niche product. Premium pricing works only when the premium is real. Right now, for most enterprise work, it isn't.
And if you're buying enterprise software built on assumptions about what humans need to do manually, you should be watching these model releases more closely than earnings reports. The pricing spread collapsed. The capability spread is next.
Frequently Asked Questions
How does Sonnet 4.6 compare to Opus 4.6 on benchmarks?
On most enterprise benchmarks, Sonnet 4.6 matches or beats Opus 4.6. It scored higher on GDPval-AA (1633 vs 1606) and agentic financial analysis (63.3% vs 60.1%). On coding (SWE-bench), Opus leads by just 1.2 points. On computer use (OSWorld), the gap is 0.2 points. The $3 model effectively matches the $15 one.
Why would Anthropic undercut its own premium product?
Anthropic is running a volume strategy. Customers spending $100K+ annually grew sevenfold year over year. Million-dollar accounts went from 12 to over 500. At $3 per million tokens, enterprises deploy more agents, consume more tokens, and lock in deeper. The $380 billion valuation depends on infrastructure-scale adoption, not luxury margins.
What is computer use and why does it matter for enterprise software?
Computer use lets AI models interact with software visually, clicking buttons, filling forms, and navigating screens like a human. Most business software lacks APIs and was designed for manual operation. A model scoring 72.5% on OSWorld can handle these tasks without custom integrations, potentially replacing the middleware many SaaS companies sell.
What did Vending-Bench Arena reveal about Sonnet 4.6?
Vending-Bench Arena simulates autonomous businesses where AI models make investment and pricing decisions for a full year without human input. Sonnet 4.6 spent heavily for ten months building capacity, then pivoted to profitability, finishing at roughly $5,700 versus Sonnet 4.5's $2,100. It demonstrated genuine long-horizon planning capability.
Does Opus 4.6 still have advantages over Sonnet 4.6?
Yes, but they are narrowing. Opus leads on the hardest reasoning tasks including codebase refactoring, multi-agent coordination, and problems requiring maximum precision. On SWE-bench coding, Opus scores 80.8% to Sonnet's 79.6%. For work where accuracy justifies five times the cost, Opus remains the choice. For most enterprise work, the price gap no longer matches the performance gap.




Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


