💡 TL;DR - The 30 Seconds Version
👉 Anthropic ditches 30-day data deletion for Claude consumers, offering 5-year retention if users opt into AI model training by September 28, 2025.
📊 Policy affects millions on Free, Pro, and Max tiers but exempts all commercial users including enterprises, government, and API customers.
🔄 Users can reverse decisions anytime, but data already used in completed training cycles stays permanently in those models.
⚠️ Only "new or resumed" chats become training data—opening old conversations changes their status and makes them eligible for collection.
🏭 Five-year retention matches AI development cycles that take 18-24 months, plus time for safety testing and abuse pattern detection.
🌍 Move signals industry-wide shift as major AI companies face identical pressures for high-quality training data amid slowing compute scaling returns.
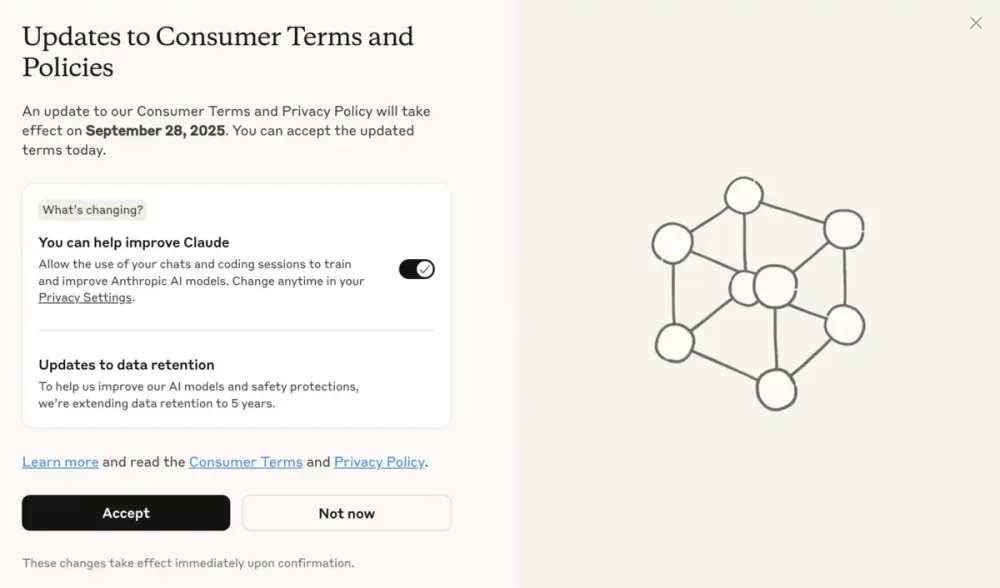
Anthropic is recasting privacy for Claude’s consumer tiers. The company will ask every Free, Pro, and Max user to decide whether new and resumed chats and coding sessions can be used to train future models. If you allow it, Anthropic will retain those interactions for up to five years instead of the prior 30 days. Decline, and the 30-day retention policy remains.
A decision is required by September 28, 2025. Existing users will see an in-app prompt and can defer once with “Not now,” but they must choose by that date to keep using Claude. New users make the choice during signup. That’s the tension: convenience nudges acceptance; privacy demands deliberation.
What’s actually changing
The training toggle applies only to new or resumed activity. Old chats stay out unless you reopen them. Resume an unfinished coding session and the thread becomes eligible for training going forward. Delete a conversation and it won’t be used in future training runs.
Anthropic says the switch can be flipped at any time. Turning it off halts use of future chats and coding sessions. What it does not do is untrain an already trained model. Data used in a past run remains part of the models built from it. That’s standard across the industry, but it matters.
Where the line is drawn
The policy excludes commercial tiers. Claude for Work, Team, and Enterprise customers, along with Claude Gov, Claude for Education, and API usage via Anthropic, Amazon Bedrock, or Google Cloud’s Vertex AI, are not covered by the consumer toggle. Those buyers expect strict contractual controls, and they have leverage to demand them.
Consumer usage is different. It ranges from brainstorming and study help to hobby coding—material that can improve model reasoning and guardrails without exposing corporate secrets. Anthropic says it uses automated tools to filter or obfuscate sensitive data and does not sell user data to third parties. That’s table stakes, but still worth stating.
Why five years—and why now
Model development happens on long arcs. Building, testing, and shipping a new frontier-scale LLM can take 18–24 months, followed by safety tuning and deployment windows. Short retention periods make it harder to assemble consistent, longitudinal datasets that keep upgrades smooth and behavior stable. Five years gives Anthropic multiple cycles of comparable data.
Safety systems also learn from patterns, not one-offs. Abuse, spam, and coordinated misuse become clearer when observed across time. Extending retention helps improve those classifiers. The trade-off is obvious: longer retention increases the privacy and breach exposure window. That’s the unavoidable balance of signal versus surface area.
The consent experience, not just the policy
User-experience choices shape outcomes. The pop-up arrives when people want to get work done, which can nudge quick acceptance. According to reporting in The Verge, the dialog includes a prominent “Accept” button and a smaller training toggle that defaults to on. That design invites accidental consent. The “Not now” escape valve helps, but only once. Clear labeling and equal-weight controls would better align with meaningful choice.
A second friction point is “resumed chats.” Many users dip back into long threads. They may not realize that reopening a conversation changes its status for training. Anthropic explains this in its FAQ, but the behavior will surprise some people in practice.
Competitive and regulatory context
Every major lab faces the same constraint set: soaring compute costs, limited high-quality data, and regulators scrutinizing AI safety, privacy, and provenance. Opt-in consumer training is one way to harvest fresh, high-signal interactions while preserving stricter promises for enterprise and government buyers. It’s also a hedge against allegations of scraping or opaque data sourcing.
Expect peers to converge on similar architectures: explicit user choice, long retention for those who opt in, per-conversation deletion, and carve-outs for commercial tiers. The design details—default states, wording, placement—will reveal each company’s real priorities.
Limitations and open questions
Filtering “sensitive data” is hard. Automated obfuscation can miss edge cases or misclassify personal information tucked inside code comments, file paths, or screenshots. Anthropic’s description of its filters is high-level; external audits or red-team results would add trust. Another unresolved area is team accounts that span consumer and business contexts, where boundaries can blur as features evolve.
There’s also the reality that consent, once given, can’t unwind models already trained. That’s not a bug so much as a property of gradient-based learning, but it underscores the importance of the initial choice—and of making that choice conspicuous, reversible for the future, and easy to understand.
Why this matters:
- The default is shifting. A five-year retention option for consumer chats resets expectations for how AI firms collect and keep behavioral data, even as opt-outs persist for privacy-minded users.
- Data beats rhetoric. Real user interactions remain the scarcest fuel for better models and safer guardrails, so how consent is gathered—and how deletions are honored—will be a core competitive and regulatory battleground.
❓ Frequently Asked Questions
Q: What happens to my old conversations if I opt out entirely?
A: They stay completely untouched and get deleted after 30 days as before. Only conversations you start fresh or actively resume after making your choice are affected. Your chat history before the September 28 deadline remains under the old policy regardless of your decision.
Q: How does Anthropic filter out sensitive information from training data?
A: The company uses "automated processes to filter or obfuscate sensitive data" but hasn't specified exact methods. This likely includes detecting credit card numbers, Social Security numbers, and other personally identifiable information. However, no automated system catches everything, especially context-dependent sensitive information.
Q: Can I see what data Anthropic has collected from me for training?
A: The company hasn't announced a data access portal. You can see your conversation history in Claude's interface and delete individual chats to remove them from future training. Once conversations are incorporated into a completed training run, they can't be extracted from that model.
Q: Why don't commercial customers get asked about training data?
A: Enterprise, government, and API customers pay higher rates and expect strict contractual data protection. Their conversations often contain proprietary business information, classified materials, or regulated data that legally can't be used for training. Consumer chats are typically less sensitive and more useful for general model improvement.
Q: What exactly counts as "resuming" an old conversation?
A: Any new message added to an existing chat thread after you've opted into training. This includes continuing a coding session from last week or adding one more question to a months-old conversation. The entire thread history becomes eligible for training, not just your new messages.

Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


