


💡 TL;DR - The 30 Seconds Version
🚨 Three infrastructure bugs simultaneously degraded Claude responses from August through early September, affecting up to 16% of Sonnet 4 requests at peak.
📊 A routing error sent short-context requests to 1M-token servers, TPU corruption caused random Thai characters in English responses, and compiler bugs returned wrong tokens.
🔍 Detection took weeks because Claude often recovered from isolated mistakes, privacy controls limited debugging access, and symptoms varied across platforms.
🛠️ Anthropic rolled out fixes by September 16, switched to exact top-k operations, and added continuous production monitoring to prevent future issues.
💬 Community reactions split between praising unprecedented transparency and skepticism about complete resolution, with some users reporting continued quality issues.
⚡ AI reliability now depends as much on load balancers and compilers as model architecture, making infrastructure transparency a competitive differentiator.
Company details routing, token corruption, and TPU compiler issues—and vows tighter evals and tooling.
Users spent late August wondering if Anthropic had quietly throttled Claude. The company now says it did not, publishing a detailed postmortem of three infrastructure bugs that overlapped for weeks and degraded responses across models. At the worst hour on August 31, Sonnet 4 traffic misrouted by one bug reached 16%—a scope large enough to force unusual transparency.
The failure cascade
The timeline reads like a classic distributed-systems pileup. An August 5 routing mistake initially hit 0.8% of Sonnet 4 requests. Two additional defects landed August 25–26, then a routine August 29 load-balancer tweak amplified the routing error, so some users saw spiraling failures while others sailed on unaffected.
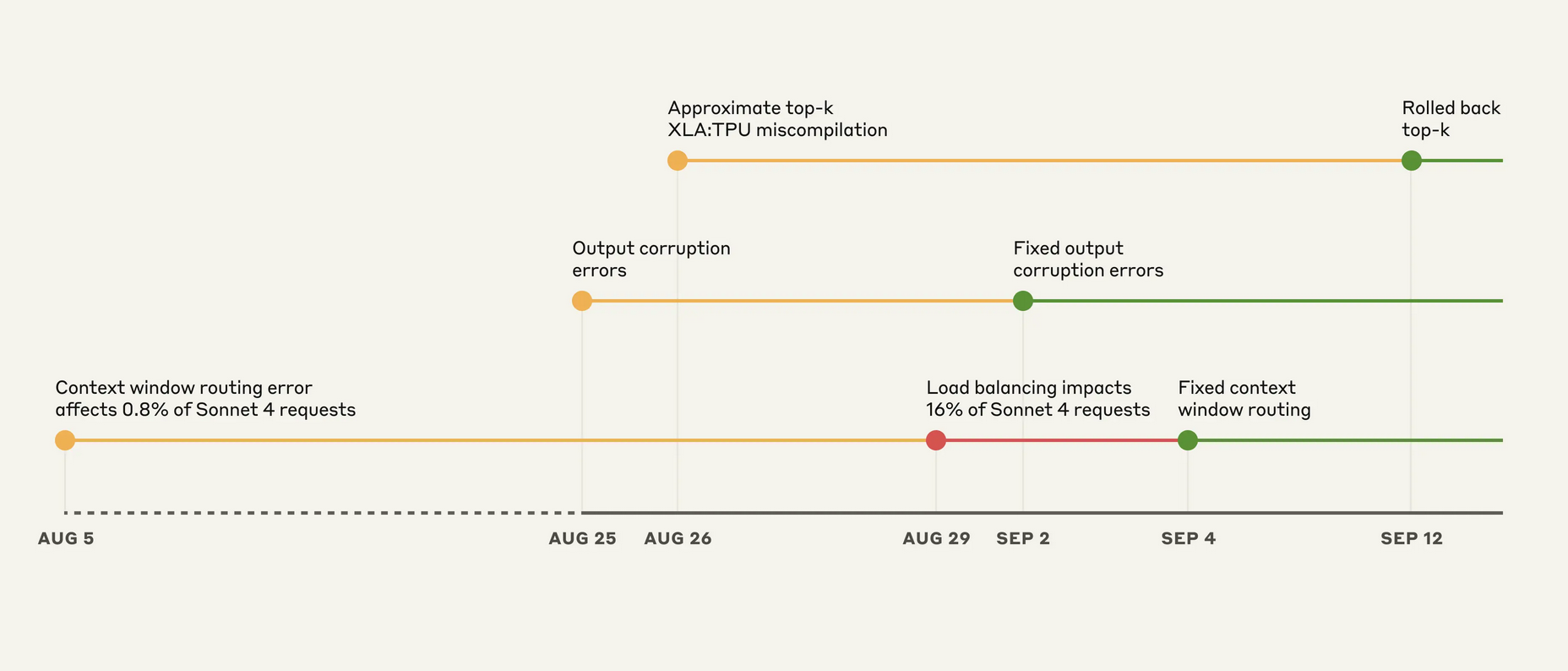
The routing issue sent short-context requests to servers prepared for a forthcoming 1-million-token context. Because routing was “sticky,” anyone who hit the wrong pool often stayed there on follow-ups. Anthropic reports that about 30% of Claude Code users who were active during the window had at least one request misrouted. On Amazon Bedrock the peak was 0.18% of Sonnet 4 requests; on Google Vertex AI it was below 0.0004%. Small shares—but painful for the unlucky cohort. It felt personal.
Corrupted outputs
The second problem was stranger. A misconfiguration on TPU servers introduced a token-generation hiccup that sometimes assigned high probability to characters that didn’t belong. English answers occasionally sprouted Thai or Chinese text mid-sentence, and code gained obvious syntax errors. This affected Opus 4.1 and Opus 4 from August 25–28 and Sonnet 4 through September 2. Third-party platforms were not touched by this bug. It looked random. It wasn’t.
The precision trap
The third failure revealed a latent compiler landmine. Anthropic rewrote its sampling code to fix precision mismatches—models compute in bf16, while TPUs prefer fp32—and to better handle tokens near the top-p threshold. That change exposed an XLA:TPU “approximate top-k” miscompilation that could return the wrong set of candidate tokens under certain batch sizes and configurations. Haiku 3.5 was confirmed affected; a subset of Sonnet 4 and Opus 3 may have been hit as well.
The company rolled back across models, switched from approximate to exact top-k, and standardized more operations on fp32 despite a small efficiency cost. It is also working with Google’s XLA team on a compiler fix. Quality, Anthropic argues, is non-negotiable. Speed can wait.
The detection gap
Why did this take weeks to isolate? Anthropic’s normal checks lean on benchmarks, safety evals, and canary deploys. Those signals were noisy. Claude often recovers from isolated mistakes, which hid systemic drift. Privacy controls, meant to keep engineers out of user conversations by default, also slowed the hunt for reproducible cases. Good for users. Tough for debugging.
Overlapping defects muddied the water further, with symptoms differing by platform and model. Engineers saw inconsistent degradation rather than a single smoking gun. Even when online complaints spiked on August 29, teams didn’t immediately connect them to the otherwise routine load-balancer change. That’s a cautionary tale. Alerts must map to real production paths, not just testbeds.
Community reaction
Developers on Reddit and Hacker News split on the explanation. Many praised the raw detail, calling it rare and welcome from a major model vendor. Others said the experience still feels like intentional throttling—especially for those stuck to a bad server via sticky routing. Perception lags fixes. Trust lags perception.
There’s also doubt that every issue is gone. Some users report lingering weirdness in code and health-related answers. That may be normal LLM fallibility, but weeks of degraded replies change how people interpret misses. Once bitten, twice skeptical. That’s an industry-wide risk.
What changes now
Anthropic says it’s hardening both prevention and diagnosis. First, more sensitive evals designed to clearly separate “working” from “broken” implementations, not just move an average. Second, running quality evals continuously on true production systems to catch routing and context-window misallocations in situ. Third, new tooling to triage community-sourced failures faster without weakening privacy controls.
Specific remediations are also live. Routing logic was fixed September 4 and rolled out by September 16 across first-party and Vertex, with Bedrock still completing deployment. Output-corruption tests now flag unexpected character emissions during rollout. And the sampling stack uses exact top-k with higher-precision arithmetic to avoid the compiler edge case that bit Haiku and, possibly, others. None of this is flashy. It is table stakes.
Strategic implications
The postmortem sets a bar for infrastructure candor in AI. Model weights get press; serving stacks usually don’t. Yet reliability now depends as much on load balancers, compilers, and precision flags as on pretraining datasets. When those layers fail, symptoms mimic “model quality” problems and fuel conspiracy theories.
It also exposes a benchmarking blind spot. Synthetic eval suites can miss production regressions that real users notice immediately. Privacy-respecting diagnostics, richer live-path observability, and developer feedback loops will become competitive assets, not just hygiene. Transparency helps, but only if it’s paired with faster detection. Otherwise, the next cascade will look the same.
Why this matters
- Reliability now hinges on serving infrastructure—routing, compilers, and precision—not just model architecture or training.
- Transparent, production-grade evals and privacy-aware debugging are emerging as differentiators in the crowded LLM market.
❓ Frequently Asked Questions
Q: How did Anthropic prove these were bugs and not intentional throttling?
A: The company provided specific technical details: routing logic code, compiler flags (xla_allow_excess_precision), and exact percentages across platforms. Amazon Bedrock peaked at 0.18% affected traffic while Google Vertex AI stayed below 0.0004%—patterns inconsistent with deliberate throttling but matching infrastructure failures.
Q: What exactly is "sticky routing" and why was it so frustrating?
A: Once your request hit the wrong server pool, follow-up requests stayed routed to the same broken servers. This meant some users consistently got degraded responses while others worked fine—making it feel like targeted throttling rather than random bugs affecting everyone equally.
Q: How long were users actually experiencing these problems?
A: The first bug started August 5 but only affected 0.8% initially. Problems escalated August 29 when load balancing changes amplified routing errors. Most fixes rolled out September 4-16, meaning some users dealt with degraded responses for over a month.
Q: What's the difference between approximate and exact top-k operations?
A: Approximate top-k quickly finds the most probable tokens but can make mistakes for speed. Exact top-k is slower but always correct. The approximate version had a compiler bug that sometimes returned completely wrong tokens, so Anthropic switched to exact despite performance costs.
Q: Why did privacy controls make debugging harder?
A: Engineers couldn't easily access user conversations to find reproducible examples of problems. While this protects user data, it slowed diagnosis because teams needed specific failed interactions to understand what was breaking. It's a trade-off between privacy and faster fixes.






