


San Francisco | February 13, 2026
Tim Cook's $600 billion shield cracked. Apple shed 5% after the FTC accused Apple News of political bias, and Bloomberg reported Siri's AI overhaul is failing internal tests. Political goodwill and product credibility, both gone in a single afternoon.
Shanghai isn't waiting. MiniMax dropped M2.5, matching Opus on coding benchmarks at one-twentieth the price. Five Chinese labs shipped in one week. The cost war looks like solar panels all over again.
Google's Gemini 3 Deep Think posted 84.6% on ARC-AGI-2. GPT-5 managed 53%. Claude hit 69%. The reasoning gap isn't closing.
Stay curious,
Marcus Schuler
Apple Stock Drops 5% as FTC Warning and Siri AI Delays Hit Same Day

Tim Cook spent six months building a $600 billion political shield. It cracked in a single Wednesday afternoon when the FTC and Bloomberg hit Apple from opposite directions.
In August, Cook walked into the White House carrying a plaque on a 24-karat gold base and pledged Apple would spend $600 billion in U.S. operations over four years. Trump promised tariff exemptions. The arrangement held through the fall. Then Cook posted a selfie with Bad Bunny after the Super Bowl halftime show. Trump had already called the performance "an affront to the greatness of America." The Financial Times reported Cook told staff he'd push the administration on immigration enforcement. Hours before that internal meeting, he'd attended a screening of Melania Trump's documentary at the White House.
FTC Chairman Andrew Ferguson sent a warning letter accusing Apple News of systematically favoring left-leaning publications. Both FCC Chairman Brendan Carr and the White House press secretary amplified the criticism within an hour. Bloomberg reported that internal testing of Siri's AI overhaul is going so badly that it's pushing, iOS 26.4 past its spring target. Siri sometimes fails to process queries entirely. Other times it responds too slowly for users to wait.
Apple gave CNBC five words. "Still on track to launch in 2026." These are the first Siri features running on Google's Gemini models under a partnership announced in January. Ship them late and buggy, and the entire bet on Google starts looking like a mistake. UBS downgraded the U.S. tech sector to neutral the same week.
Neither crisis alone would have triggered a 5% drop. But both arriving on the same Wednesday told a story no PR team could control. A company that had spent decades building the most careful corporate diplomacy in tech lost control of its political and product narratives in a single afternoon.
Why This Matters:
- Cook's political playbook depended on both spending and silence. The Bad Bunny selfie and immigration comments broke the silence. The FTC letter is the cost.
- The iOS 26.4 beta drops later this month. If meaningful Siri features don't appear, expect downgrades and harder questions about the Gemini partnership.
✅ Reality Check
What's confirmed: Apple fell 5% Wednesday. FTC sent a warning letter on Apple News bias. Bloomberg reported Siri failing internal tests, iOS 26.4 missing its spring target.
What's implied (not proven): Cook's political strategy with the Trump administration has fundamentally broken, not just strained.
What could go wrong: FTC letters carry no enforcement power. Ferguson admitted as much. The Siri delay may resolve in the next beta cycle.
What to watch next: iOS 26.4 beta later this month. Functional Siri features reset the narrative. Another delay triggers downgrades.

The One Number
100,000+ — Prompts fired at Google's Gemini in a single campaign by commercially motivated attackers trying to clone the model through extraction. Google's Threat Horizons report disclosed the attempt this week, the largest known extraction attack on a production AI chatbot. Google says it blocked the effort. It did not say how close the attackers got.
MiniMax M2.5 Matches Opus at 5% of the Cost, Five Chinese Labs Ship in One Week

Anthropic's Opus 4.6 celebration lasted seven days. MiniMax just proved the margin is optional.
MiniMax released M2.5 in Shanghai on Wednesday. A Mixture of Experts model, 230 billion parameters total, only 10 billion active per query. On SWE-Bench Verified, the coding benchmark enterprise buyers care about most, M2.5 scored 80.2%. Opus 4.6 scores 80.8%. The gap is 0.6 percentage points. In BrowseComp and BFCL multi-turn tool-calling, MiniMax leads both Claude and GPT outright.
The price sheet tells the real story. M2.5 costs $1.35 per million tokens total. Opus runs $30. GPT-5.2 runs $15.75. One hour of continuous generation on MiniMax costs one dollar. The same hour on Opus costs twenty.
MiniMax didn't ship alone. Zhipu AI launched GLM-5, sending its Hong Kong stock up 30%. DeepSeek upgraded its flagship. Ant Group dropped Ming-Flash-Omni 2.0. ByteDance launched Seedance 2.0. Five major Chinese AI releases in a single week. Chinese Premier Li Qiang called for "scaled and commercialized application of AI" the same day.
The pricing pressure is structural. M2.5's sparse architecture fires only 10 billion of 230 billion parameters per query. Dense models like Opus fire every parameter every time. Western labs cannot cut prices by 95% without destroying the margins that fund their research operations and valuations.
Why This Matters:
- Enterprise procurement now faces a 20x price gap for functionally identical benchmark performance. The generic drug playbook says that gap doesn't survive contact with spreadsheets.
- By summer, a dozen Chinese models will likely occupy the same performance band at similar cost points. The pressure becomes structural, not promotional.

AI Image of the Day

Prompt: editorial fashion portrait, close-up, low angle, Two twenty-year-old blonde european girls in soft blue plaid dresses, sitting at a surreal garden table, with long straight blonde hair, porcelain skin, serene, detached expressions, eating with silver cutlery, behind them garden sculptures, whimsical topiary shapes, pastel color palette, soft natural lighting, minimalist landscape, natural daylight creating subtle highlights on the nose, cheeks, and forehead, visible pores, fine hair, and natural skin imperfections preserved, high-end, no retouching, no skin smoothing
Google Gemini 3 Deep Think Scores 84.6% on ARC-AGI-2, Beating GPT-5 and Claude

Google's reasoning model doesn't just lead the benchmark. It laps the field by 15.8 percentage points.
Gemini 3 Deep Think posted 84.6% on ARC-AGI-2, the reasoning benchmark designed to resist memorization. OpenAI's GPT-5.2 Thinking scored 52.9%. Anthropic's Claude Opus 4.6 Thinking hit 68.8%. Humans average about 60%. The ARC Prize Foundation verified the results independently at $13.62 per task.
The lead holds across every major test. Deep Think scored 48.4% on Humanity's Last Exam without tools, beating Claude at 40% and GPT-5.2 at 34.5%. Its Codeforces Elo of 3,455 puts it in "Legendary Grandmaster" territory. Gold-medal results on the 2025 International Olympiads in math, physics, and chemistry.
Google paired the numbers with real-world demos. A Rutgers mathematician caught a logical flaw in peer-reviewed research using the system. Duke University's Wang Lab optimized crystal growth fabrication methods. Google also introduced Aletheia, an autonomous math research agent that runs investigations independently or collaborates with humans.
The catch is cost and access. Deep Think is available only to Google AI Ultra subscribers and through a restricted early-access API. At $13.62 per task, inference at production scale gets expensive fast. Google's own Gemini 3 Pro, without the reasoning mode, scored 31.1% on the same test. The gap shows it's the extended compute doing the heavy lifting, not the base architecture.
Why This Matters:
- The 15.8-point gap over Claude represents the largest lead in reasoning any lab has held this generation. Google built that margin through test-time compute, not architecture alone.
- ARC-AGI-1 is already at 96%. If it's harder, the sequel follows the same curve, the industry will need tougher tests or shift the conversation entirely to real-world output.

🧰 AI Toolbox
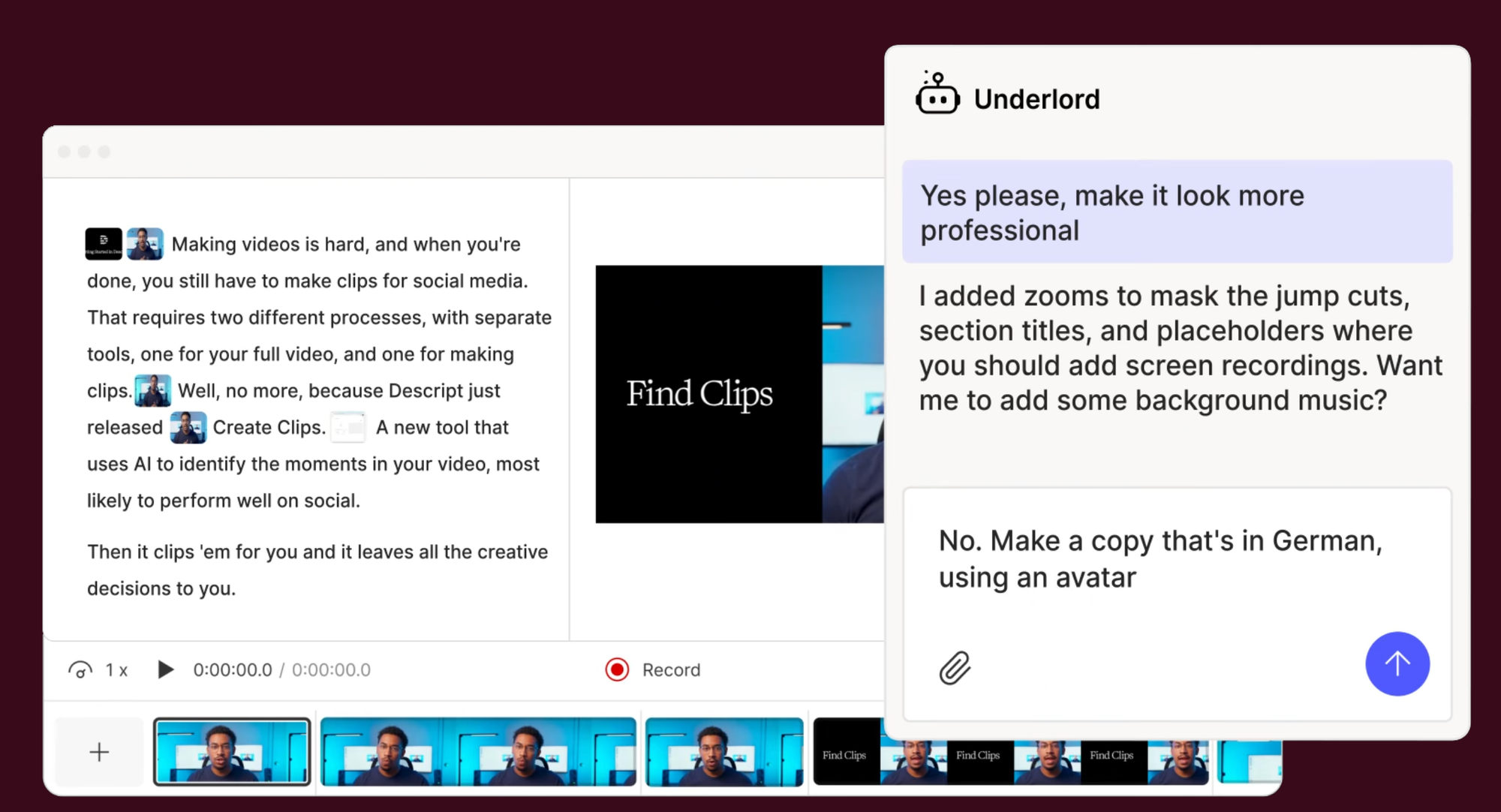
How to Edit Video by Editing Text with Descript
Descript turns video and podcast editing into a word processing task. Upload footage, get an automatic transcript, then cut, rearrange, and polish your video by editing the text. Its Underlord AI co-editor takes natural-language instructions and applies edits across your project, from removing filler words to generating highlight clips.
Tutorial:
- Sign up free at descript.com and create a new project
- Upload your video or audio file and wait for automatic transcription (usually under a minute)
- Read the transcript and delete any sections you want to cut — the video edits itself to match
- Highlight filler words like "um" and "uh" and remove them all with one click
- Open Underlord and type a plain-language instruction ("add a title card at the beginning" or "cut this down to 3 minutes")
- Use AI Eye Contact to fix moments where the speaker looked away from camera
- Export as MP4, publish directly to YouTube, or share a review link with your team
What To Watch Next (24-72 hours)
when it is not
- Applied Materials: Q1 beat sent the stock up 12% after hours Thursday, while the Nasdaq dropped 2% in the regular session. Friday's open reveals whether semiconductor equipment demand can defy the broader AI selloff.
- President's Day Earnings Wave: Markets closed Monday. Tuesday delivers DoorDash, Booking.com, and eBay. DoorDash, down 8% Thursday on AI disruption fears, faces the sharpest scrutiny.
- Trump-China Tech Truce: The administration shelved semiconductor export curbs ahead of an April Trump-Xi summit. Watch for congressional pushback after OpenAI's memo accusing DeepSeek of distilling U.S. models landed on Capitol Hill the same day.
🛠️ 5-Minute Skill: Turn a Job Listing Into a Tailored Cover Letter
You found a role that fits. The listing is dense — twelve bullet points of requirements, four "nice-to-haves," and a paragraph about company culture that mentions "fast-paced" three times. You could spend an hour writing from scratch, or you could let AI do the structural matching while you keep your voice.
Your raw input:
Job: Senior Product Manager, AI Platform — DataForge (Series B, 120 employees, SF)
Requirements:
- 5+ years product management in B2B SaaS
- Experience shipping ML/AI features to production
- Strong SQL, comfort with data pipelines
- Track record of working cross-functionally with engineering and design
- Experience with pricing and packaging
Nice-to-have: prior startup experience, familiarity with LLM APIs
My background:
- 6 years PM, last 3 at Segment (now Twilio) on data infrastructure
- Shipped ML-powered audience builder used by 400+ enterprise accounts
- Rebuilt pricing tiers from usage-based to hybrid model, grew ARR 23%
- Led cross-functional team of 8 engineers + 2 designers
- SQL daily, built internal dashboards in Looker
- No direct LLM API experience but built integrations with OpenAI embeddings for search
The prompt:
You are a hiring manager who has read 200 cover letters this month. Most are generic. Write the one that would make you stop scrolling.
From this job listing and my background, write a cover letter that:
1. Opens with a specific accomplishment that maps to their #1 requirement (not "I'm excited to apply")
2. Connects exactly 3 of my experiences to their requirements — the 3 strongest matches
3. Acknowledges one gap honestly and reframes it as adjacent experience
4. Closes with a concrete question about their product, showing I've thought about the role
5. Total: under 250 words
Job listing:
[paste listing here]
My background:
[paste your background here]
Rules:
- First person. Confident, not arrogant. No "passionate" or "driven."
- Every sentence must contain a specific fact, number, or company name.
- If a match is a stretch, don't claim it. Acknowledge the gap.
- No "I believe I would be a great fit." Show it through the examples.
What you get back:
When I rebuilt Segment's pricing from pure usage-based to a hybrid model, enterprise ARR grew 23% in two quarters. That project required the exact combination DataForge is hiring for: deep product instinct, SQL-level comfort with data, and the ability to get eight engineers and two designers rowing in the same direction.
Three things stand out about this match. First, I spent three years building data infrastructure products at Segment's scale — 400+ enterprise accounts, complex pipelines, real production stakes. Second, I shipped an ML-powered audience builder that moved from prototype to general availability, which taught me what it takes to productionize AI features when the model is only half the problem. Third, I've done the pricing and packaging work firsthand, not as a side project but as the core bet that grew revenue.
I haven't built directly on LLM APIs in production, but I've worked closely with OpenAI's embedding models for a search feature integration and understand the API patterns, latency trade-offs, and cost management involved.
One question: DataForge's platform page mentions "enterprise-grade" AI but the team is 120 people. How are you thinking about the tension between shipping fast and meeting enterprise compliance requirements? That balance defined my last two years at Segment, and I'd want to know how you're navigating it.
Why this works
The prompt forces the model to work from your actual data instead of generating corporate filler. The "hiring manager who has read 200 letters" framing shifts the AI from "write something impressive" to "write something that survives a 10-second scan." The gap acknowledgment builds credibility — it tells the reader you actually read the listing instead of mass-applying.
Where people get it wrong: Pasting a job listing and asking for "a cover letter." The AI will match every requirement and claim you're perfect for all of them. Hiring managers spot that immediately. Specificity and honesty beat completeness.
What to use
Claude (Sonnet 4.5 via claude.ai): Best at honest gap framing. Won't oversell your qualifications. Produces natural first-person voice. Watch out for: Can be too measured. If the letter feels flat, ask for more directness.
ChatGPT (GPT-4o): Strong at punchy opening lines and confident tone. Good at mirroring company language from the listing. Watch out for: Tends to claim every requirement is met, even when it is not. Check the gap section carefully.
Bottom line: Claude for honesty, ChatGPT for confidence. Read the output aloud. If it sounds like every other application, rewrite the opening.
AI & Tech News
OpenAI Accuses DeepSeek of Distilling U.S. Models in Congressional Memo
OpenAI sent a memo to U.S. lawmakers accusing Chinese AI lab DeepSeek of training its R1 model by distilling outputs from American AI systems. The company urged Congress to address what it called "free-riding" on U.S. AI research, escalating the IP fight between American and Chinese labs.
Trump Administration Shelves China Tech Curbs Ahead of April Xi Summit
The White House has paused several technology restrictions targeting China, including data center equipment curbs, ahead of a planned Trump-Xi meeting in April. The move signals a broader trade detente as both sides work to set the table for the presidential summit.
Russia Blocks WhatsApp Nationwide, Pushes State-Owned Messaging App
Russia has completely blocked Meta's WhatsApp, citing the company's refusal to comply with local laws. The Kremlin is promoting its state-owned messaging app Max as the replacement for millions of Russian users.
Applied Materials Beats Estimates, Stock Surges 12% on AI Chip Demand
Applied Materials reported $7.01 billion in Q1 revenue, beating the $6.86 billion consensus, and issued guidance above expectations. Shares jumped 12% after hours on strong demand for semiconductor equipment tied to AI and advanced memory chips.
Hollywood Demands ByteDance Rein In Seedance 2.0 Over Copyright Claims
The Motion Picture Association accused ByteDance of training Seedance 2.0 on copyrighted material "on a massive scale" without authorization. The MPA is pushing ByteDance to curb the AI video generator's capabilities, adding another front to Hollywood's fight with AI companies.
Meta Plans Facial Recognition for Ray-Ban Smart Glasses by Year-End
Meta is building a feature that would let wearers identify strangers with public Meta accounts through its smart glasses, according to the New York Times. An internal memo reportedly noted the company believed political turbulence would deflect criticism of the launch.
Stripe, OpenAI, Anthropic Lead Wave of Pre-IPO Employee Cash-Outs
Major private tech companies are letting employees sell shares before going public, breaking a long-standing Silicon Valley taboo. The trend, driven by the AI boom and extended IPO timelines, now spans Stripe, OpenAI, Anthropic, Databricks, and SpaceX.
Higgsfield AI Hits $300M ARR in 11 Months but Faces Creator Backlash
AI video startup Higgsfield reached $300 million in annual recurring revenue within 11 months of launch, but a Forbes investigation found aggressive marketing tactics including racist content and unpaid creators. The report raises questions about whether the startup's growth came at the cost of ethical standards.
Ring Cancels Flock Safety Surveillance Partnership After Backlash
Amazon's Ring has canceled its planned integration with surveillance company Flock Safety that would have let police request video directly from doorbell cameras. Weeks of public pressure over privacy concerns, compounded by a controversial Super Bowl ad, forced the reversal.
Baidu Integrates OpenClaw AI Across Search and E-Commerce
Baidu announced plans to embed OpenClaw directly into its flagship search app and e-commerce operations. The integration signals Baidu's strategy to leverage the viral AI tool to strengthen its core business across China's competitive tech market.
🚀 AI Profiles: The Companies Defining Tomorrow
Simile

Simile thinks focus groups are obsolete. The Bay Area startup builds AI simulations of real people to predict how humans will behave before they actually do. 🧠
Founders
Joon Sung Park finished his Stanford PhD in 2025 and turned his thesis into a company. His "Generative Agents" paper, co-authored with fellow co-founders Michael Bernstein and Percy Liang, collected 10,000+ citations and 20,600 GitHub stars. Lainie Yallen, employee #8 at Hebbia AI, runs the business side. The team has roughly 10 people.
Product
A foundation model for human behavior. Simile interviews hundreds of real people, feeds that data alongside historic transactions and behavioral science research into its system, then builds AI agents that replicate those people's preferences and decisions. Companies run simulations against these synthetic populations to test products, messaging, and strategy before committing real money. CVS Health uses it to decide what to stock. Wealthfront expanded its qualitative research scope 15x.
Competition
Aaru hit a $1B headline valuation in December 2025 with its own behavioral AI agents. Artificial Societies (Y Combinator) runs 500,000 AI personas for clients including Anthropic. Traditional firms like Nielsen and Ipsos still control the $120B market research industry. Simile's edge: the founders literally invented the field. The generative agents architecture originated in their Stanford lab.
Financing 💰
$100M led by Index Ventures with Bain Capital Ventures, A*, and Hanabi Capital. Fei-Fei Li and Andrej Karpathy also invested. Both co-authored the ImageNet benchmark paper with Bernstein a decade ago. This is Stanford's AI inner circle writing checks for one of their own. No valuation disclosed.
Future ⭐⭐⭐⭐
The team is absurdly credentialed. Percy Liang coined "foundation model." Bernstein helped build ImageNet. Park's research defined generative agents. The risk: seven months old, roughly ten employees, and competitors already carry unicorn valuations. But nobody else has the people who wrote the papers everyone else cites. 🔬
🔥 Yeah, But...
OpenAI sent a memo to U.S. lawmakers on Wednesday, accusing Chinese AI lab DeepSeek of using distillation techniques to train its next-generation models and "free-riding" on leading American AI systems. OpenAI has been sued by The New York Times, a coalition of authors, and multiple music publishers for training its own models on copyrighted material without permission or payment.
Sources: Bloomberg, February 12, 2026
Our take: The logic is apparently directional. Absorb the world's journalism, literature, and music to train your models? That's fair use, and the lawsuits are frivolous. Does someone absorb your outputs? That's theft requiring a congressional memo. The technique OpenAI calls "distillation" when DeepSeek does it is standard machine-learning practice across the industry. The difference isn't the method. It's who's on the losing end. Somewhere in midtown Manhattan, the Times's legal team is already printing the memo and underlining the word "free-ride." OpenAI just wrote their opening argument for them.



