

💡 TL;DR - The 30 Seconds Version
👉 Disney Research created ScaffoldAvatar, a system that renders photorealistic 3D head avatars with individual freckles and wrinkles visible in real-time.
📊 The system uses 432 facial patches with 8,208 expression parameters, compared to just 100 parameters in current industry-standard methods.
🏭 ScaffoldAvatar achieves 37.03 PSNR performance scores versus 30.15 for the previous best method, while running at 100+ FPS on consumer graphics cards.
🌍 The breakthrough targets a market projected to grow from $0.80 billion in 2025 to $5.93 billion by 2032, driven by demand for realistic digital humans.
🚀 Applications include virtual telepresence, movie production, and video game characters that maintain believable detail even in extreme close-ups.
🔧 Current limitations include inability to handle accessories like glasses and lack of eye movement tracking, positioning this as early-stage technology.
Disney Research addresses a major problem with digital humans: they look fake up close. The new ScaffoldAvatar system renders photorealistic 3D head avatars that maintain crisp detail even in extreme close-ups. You can see individual freckles, dynamic wrinkles, and facial hair moving naturally.
The breakthrough comes from treating faces differently. Instead of controlling expressions globally, ScaffoldAvatar divides each face into 432 small overlapping patches. Each patch gets its own expression controls, creating 8,208 total expression parameters. Compare that to the 100 parameters in current industry-standard methods.
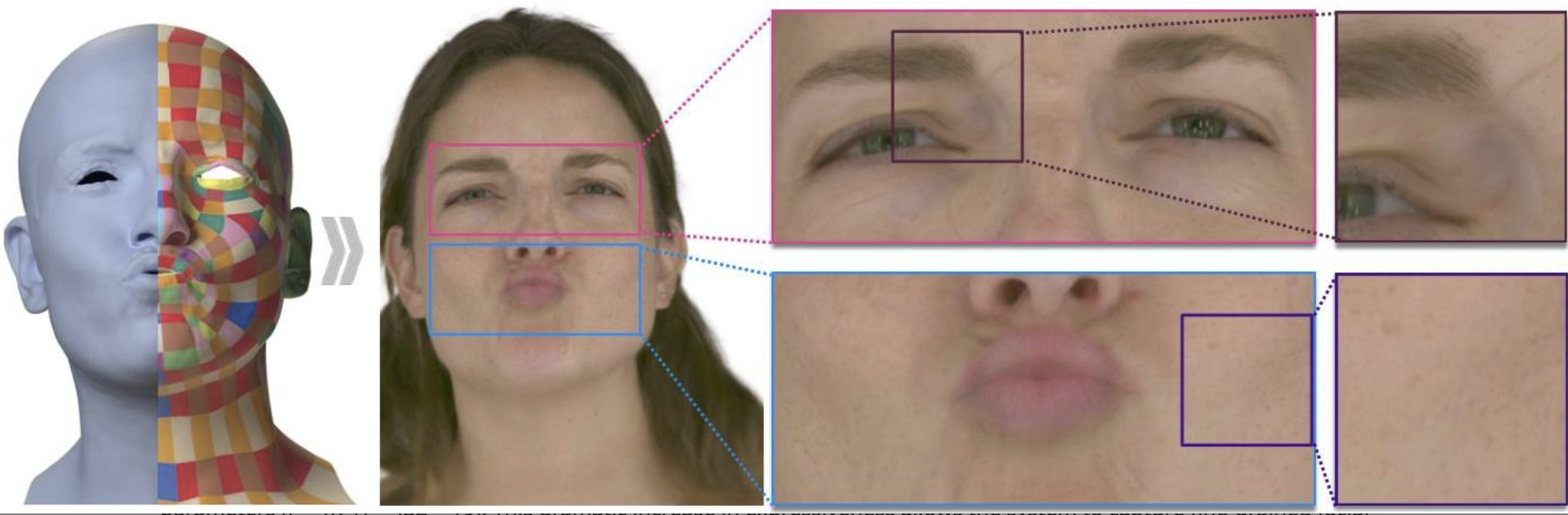
The result? Digital humans that can synthesize high frequency facial details including freckles and other fine facial features with real-time rendering. The system runs at over 100 frames per second on consumer graphics cards, making it practical for live applications.
The Uncanny Valley Problem
Digital humans have struggled with the uncanny valley for decades. They look convincing from a distance but fall apart under scrutiny. Zoom into someone's face during a video call, and you'll see the telltale signs: blurry skin texture, static-looking freckles, and expressions that seem painted on rather than lived in.
Previous methods like GaussianAvatars and Neural Parametric Gaussian Avatars made progress but still produced results that looked soft and artificial when viewed closely. The fundamental issue was their approach to facial expressions. They treated the entire face as one unit, using global expression codes that couldn't capture the subtle variations happening across different facial regions.
Think about your own face. When you smile, the corners of your mouth don't just move - the skin around your eyes crinkles, your cheeks lift, and dozens of micro-expressions happen simultaneously. Traditional systems couldn't handle this complexity without blur or artifacts.
The Patch-Based Revolution
ScaffoldAvatar's solution seems obvious in hindsight. The research team, led by scientists from Disney Research Studios and the Technical University of Munich, divided facial geometry into 432 small patches. Each patch gets its own expression model and can move independently.
This approach draws from anatomical reality. Facial muscles don't work as one unified system - they're composed of dozens of interconnected muscle groups, each capable of independent movement. The patch-based model mirrors this biological structure.
The technical implementation builds on Scaffold-GS, a hierarchical scene representation that spawns multiple 3D Gaussian primitives around anchor points. These anchors attach to patch centers on the tracked facial mesh. When expressions change, the anchors move with their patches, carrying the visual detail along.
Each patch connects to multiple machine learning networks that predict how light bounces off the skin, how shadows fall, and how surface details like pores and wrinkles should appear. The system learns these relationships from high-resolution training footage - 3,072 by 2,304 pixel images captured at 24 frames per second.
Technical Performance
The numbers tell the story. ScaffoldAvatar achieves a PSNR of 37.03 on novel view synthesis tasks, compared to 30.15 for the previous best method. On self-reenactment tests - where the system drives the avatar with new expressions - it scores 35.15 PSNR against 27.44 for the runner-up.
More importantly, the visual results speak for themselves. Side-by-side comparisons show ScaffoldAvatar rendering sharp, believable skin texture where competitors produce soft, artificial-looking results. The system captures dynamic wrinkles that appear and disappear naturally with expressions, something previous methods couldn't achieve.
The performance gains come from several technical innovations beyond the patch-based approach. The team developed a color-based densification strategy that converges faster than standard position-based methods. They also implemented progressive training, starting with lower resolution images and gradually increasing detail.
Training takes 3-4 days on professional graphics hardware, but the results run in real-time on consumer GPUs. A consumer-grade RTX 4070Ti renders the full-resolution model at 76.91 FPS, while a lower-resolution version hits 100.78 FPS.
Applications and Market Impact
The timing aligns with massive growth in the digital human market. The AI avatar market is expanding rapidly, with a projected market size rising from USD 0.80 billion in 2025 to USD 5.93 billion by 2032. ScaffoldAvatar's real-time performance and high fidelity could capture significant market share.
Virtual telepresence represents the most obvious application. Video calls could feature photorealistic avatars that maintain eye contact and natural expressions without the uncanny valley effect. Corporate meetings, remote work, and virtual events could all benefit from more believable digital representations.
Entertainment applications seem equally promising. Movie studios could create digital doubles of actors for dangerous scenes or posthumous performances. Video game characters could achieve unprecedented realism. Virtual influencers and content creators could operate with Hollywood-quality avatars.
The system also supports cross-reenactment, where expressions from one person drive another person's avatar. This opens possibilities for real-time face swapping in video calls, entertainment applications, and accessibility tools that could help people with facial paralysis or other conditions.
Current Limitations
ScaffoldAvatar isn't perfect. The system doesn't handle accessories like glasses or hats. Eye movements aren't tracked, so eyeball rotation doesn't animate correctly. The mouth interior lacks detail, and tongue movement isn't captured.
The training process requires significant computational resources and specialized multi-camera capture equipment. Each avatar must be trained individually, preventing one-size-fits-all solutions. The 432-patch approach also assumes relatively consistent facial topology, which might not work for all face shapes or expressions.
The research team acknowledges these constraints while positioning them as areas for future work rather than fundamental limitations. The core breakthrough - patch-based expression control with real-time rendering - appears solid.
Industry Response
The computer graphics community has taken notice. The work was presented at SIGGRAPH 2025, the industry's premier conference. By leveraging patch-level expressions, ScaffoldAvatar consistently achieves state-of-the-art performance with visually natural motion, while encompassing diverse facial expressions and styles in real time.
Other research groups are likely already working on similar approaches. The patch-based concept could become standard practice for digital human creation, much like how neural networks became standard for computer vision tasks.
The real test will come when ScaffoldAvatar faces commercial deployment. Laboratory demonstrations don't always translate to real-world robustness. But the technical foundation appears strong enough to handle practical applications.
Why this matters:
• The uncanny valley just got smaller - ScaffoldAvatar's patch-based approach finally delivers digital humans that look convincing in close-up, potentially transforming everything from video calls to movie production.
• Real-time photorealism is now achievable - At 100+ FPS on consumer hardware, the technology is ready for practical deployment, not just research demonstrations.
Read on, my dear:
ScaffoldAvatar: High-Fidelity Gaussian Avatars with Patch Expressions
❓ Frequently Asked Questions
Q: How much does it cost to create a ScaffoldAvatar?
A: Disney Research hasn't released pricing details since this is still research-phase technology. The system requires specialized multi-camera capture equipment and 3-4 days of training on professional graphics hardware (like an NVIDIA RTX A6000 with 48GB VRAM), suggesting high initial costs for commercial deployment.
Q: When will ScaffoldAvatar be available to consumers?
A: No commercial release date has been announced. The technology was presented at SIGGRAPH 2025 as research, indicating it's still in early development. Disney typically takes several years to move research projects into consumer products or theme park attractions.
Q: What hardware do you need to run ScaffoldAvatar?
A: For real-time playback, a consumer RTX 4070Ti (12GB VRAM) runs the full model at 76.91 FPS, while lower resolution versions hit 100.78 FPS. Training requires professional hardware like an RTX A6000 with 48GB VRAM and takes 3-4 days.
Q: How does this compare to deepfakes?
A: Unlike deepfakes that swap faces in existing videos, ScaffoldAvatar creates controllable 3D avatars from scratch. It offers real-time expression control and consistent multi-angle viewing, while deepfakes typically work on single camera angles and can't be controlled interactively.
Q: Can ScaffoldAvatar work with any face?
A: Each avatar requires individual training on that specific person's facial data. The system assumes consistent facial topology and doesn't handle accessories like glasses or hats. It also can't track eye movements or tongue motion, limiting expression range.
Q: How long does it take to create one avatar?
A: After capturing 5-8 performance sequences with the multi-camera setup, training takes 3-4 days on professional graphics hardware. The progressive training starts at 1024x768 resolution for 50,000 iterations, then moves to 3K resolution for another 50,000 iterations.
Q: What are the privacy implications of this technology?
A: The system requires extensive facial data capture - multiple camera angles, various expressions, and lighting conditions. This biometric data could be sensitive if misused. Disney Research hasn't addressed data storage, sharing, or deletion policies for the facial training data.
Q: How does the 432-patch system work?
A: The face is divided into 432 small overlapping patches, each with its own expression controls. This creates 8,208 total expression parameters compared to 100 in traditional methods. Each patch connects to machine learning networks that predict skin appearance, shadows, and surface details like wrinkles.





