


💡 TL;DR - The 30 Seconds Version
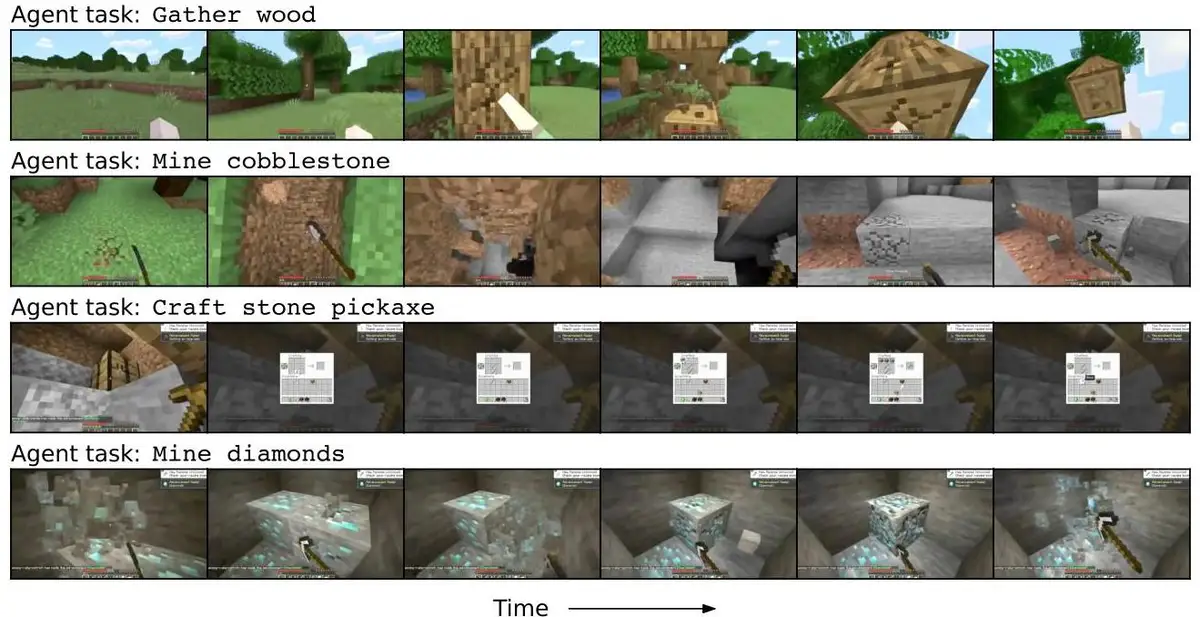
🎮 Dreamer 4 became the first agent to mine diamonds in Minecraft (0.7% success rate) using only offline video data and simulated practice—never touching the real game during training.
📊 The system needed just 100 hours of action-paired video out of 2,500 total hours to reach 85% performance, proving most world knowledge extracts from unlabeled footage.
⚡ Runs at 21 FPS on a single H100 GPU in real-time—13 to 26 times faster than competing approaches—enabling the millions of simulated rollouts required for reinforcement learning.
🧪 Human operators successfully completed 14 out of 16 complex tasks inside the simulated environment, from combat to crafting, proving the world model captures causal accuracy.
🌍 Action conditioning learned from one Minecraft environment generalized to entirely unseen dimensions with 76% accuracy, suggesting transferable physics understanding rather than memorization.
🚀 The constraint binding agent development appears to be world model quality, not RL algorithms—reshaping priorities for robotics, autonomous systems, and domains where online exploration is expensive or dangerous.
Google DeepMind says its new agent can mine diamonds in Minecraft without ever touching the real game during training. The paper backs that up: Dreamer 4 learns from offline video, then trains entirely inside its own world model to execute the 20,000-plus actions needed to reach the game’s hardest milestone.
What’s actually new
Dreamer 4 collapses two previously separate lines of work—video generation and reinforcement learning—into a single, scalable world model that can be used for policy training. The model runs at the game’s native 360×640 resolution and matches real-time play on a single H100, with a 9.6-second temporal context. That matters because agents need millions of imagined rollouts to learn long sequences; most prior simulators couldn’t keep up.
Under the hood, DeepMind introduces “shortcut forcing,” plus a shift from v-prediction (predicting velocity/noise) to x-prediction (predicting clean latents). The point is simple: reduce high-frequency error that accumulates over long rollouts. In ablations, those choices unlock fast, stable generations with a handful of sampling steps while keeping fidelity high.
Evidence, not hype
On the core benchmark—start in a fresh world with an empty inventory and play for 60 minutes—Dreamer 4 hits diamonds in 0.7% of 1,000 evaluation runs. That looks small until you compare baselines: OpenAI’s VPT, which used 2,500 hours of contractor play plus 270,000 hours of action-labeled web video, topped out at basic milestones and did not reliably progress into iron tools, let alone diamonds. Dreamer 4 uses the same 2,541-hour contractor dataset and still advances further by training its policy inside the learned simulator.
DeepMind also stress-tests the simulator with humans at the controls. Operators attempted 16 hand-crafted tasks—crafting, building, combat, navigation—purely inside each model’s imagined world. Dreamer 4 completes 14 of 16. Oasis (large) manages 5, Lucid-v1 effectively none, and MineWorld is too slow for practical testing. This is the key check: can a person perform complex actions inside your “fake” environment without it drifting into visual autocomplete? Dreamer 4 passes that bar.
Data efficiency is the headline
The most important number isn’t the 0.7%. It’s 100. Dreamer 4 learns robust action conditioning using just 100 hours of action-paired video out of 2,541 total hours; the rest can be unlabeled. With that tiny slice, the model reaches ~85% of the action-conditioned quality (PSNR/SSIM) of a fully labeled run. In a controlled test, action grounding learned in the Overworld generalizes to the Nether and End—with 76% of PSNR and 80% of SSIM relative to a model trained with all actions. Translation: most “world knowledge” comes from passive video; a little action data goes a long way.
Compute and speed, in balance
Training uses 2-billion-parameter models across 256–1,024 TPU v5p chips, then the learned world model offers interactive inference beyond 20 FPS on a single H100. Competing Minecraft simulators either fall below real-time (MineWorld ~2 FPS) or only approach it at small scale (Oasis small is real-time; Oasis large is roughly 5 FPS on one H100). For RL, those deltas are decisive—if the simulator can’t run fast, imagination training stalls.
How the agent learns
The recipe is three-phase. First, pretrain a causal tokenizer and dynamics model on video (with optional actions) to predict future frames. Second, insert “agent tokens” and fine-tune the same transformer to predict actions and rewards for multiple tasks. Third, do reinforcement learning entirely inside the model’s imagination—no online environment interaction required. It’s one architecture serving both simulation and policy learning, which tightens the loop and speeds iteration.
Where this diverges from text-to-video
Generative video aims for pretty frames on prompt. Agent world models aim for causal accuracy, long-horizon consistency, and real-time throughput. Dreamer 4 shows you can get usable visuals and precise control, but the objective is different: predict the consequences of the next action well enough to learn strategy, not to win a film festival. That difference explains why “autocomplete” failure modes doom some flashy video models in interactive tests.
The wider stakes
If you can learn competent world models from mostly unlabeled video—and only sprinkle in a little action data—you can pretrain on the internet’s archives, then specialize with small, domain-specific traces. That reframes data collection for robotics, AV, and industrial control, where online exploration is unsafe or expensive. And because inference is real-time on one GPU, you can actually use the thing.
It’s still early. Memory is short; inventories drift; success on diamonds is rare. But the constraint looks clear: world model quality, not RL trickery, is the bottleneck. Improve the simulator and the agent follows.
Why this matters
- World-model first: The binding constraint for agents is an accurate, fast simulator; better models beat bigger offline datasets and fancy RL alone.
- Safer, cheaper training: Learning from video plus imagination reduces the need for risky online exploration in robotics, vehicles, and infrastructure.






