
💡 TL;DR - The 30 Seconds Version
👉 Google's Gemini AI solved 10 of 12 problems at September's International Collegiate Programming Contest, ranking 2nd among 139 university teams, while OpenAI's models achieved perfect scores.
📊 Only four teams earned gold medals at the world's most prestigious programming competition, where contestants get five hours to solve complex algorithmic problems with zero room for error.
🏭 Gemini cracked Problem C in under 30 minutes—a liquid distribution optimization challenge that stumped every human competitor at the Azerbaijan finals.
💰 Google won't disclose computing costs, confirming only that requirements exceeded their $250-per-month consumer service capabilities.
🌍 AI reasoning now matches human expert performance on complex tasks, but economic barriers prevent widespread deployment across most applications.
🚀 Both companies proved advanced AI can handle multi-step reasoning, marking progress toward general-purpose AI systems that complement human capabilities.
OpenAI quietly achieved perfect score at same contest. Computing costs remain undisclosed barrier
Google's Gemini 2.5 Deep Think solved 10 of 12 problems at September's International Collegiate Programming Contest World Finals, earning gold medal status and ranking second among 139 university teams. The achievement marks the first time an AI model has reached elite competitive programming performance—though OpenAI's models actually solved all 12 problems for first-place equivalent results.
The ICPC is basically the Olympics for college programmers. Teams from nearly 3,000 universities across 103 countries get five hours to crack brutally complex algorithmic problems. You either nail the solution perfectly or get nothing. This year's finals in Baku, Azerbaijan, saw only four teams achieve gold medal status out of 139 competitors.
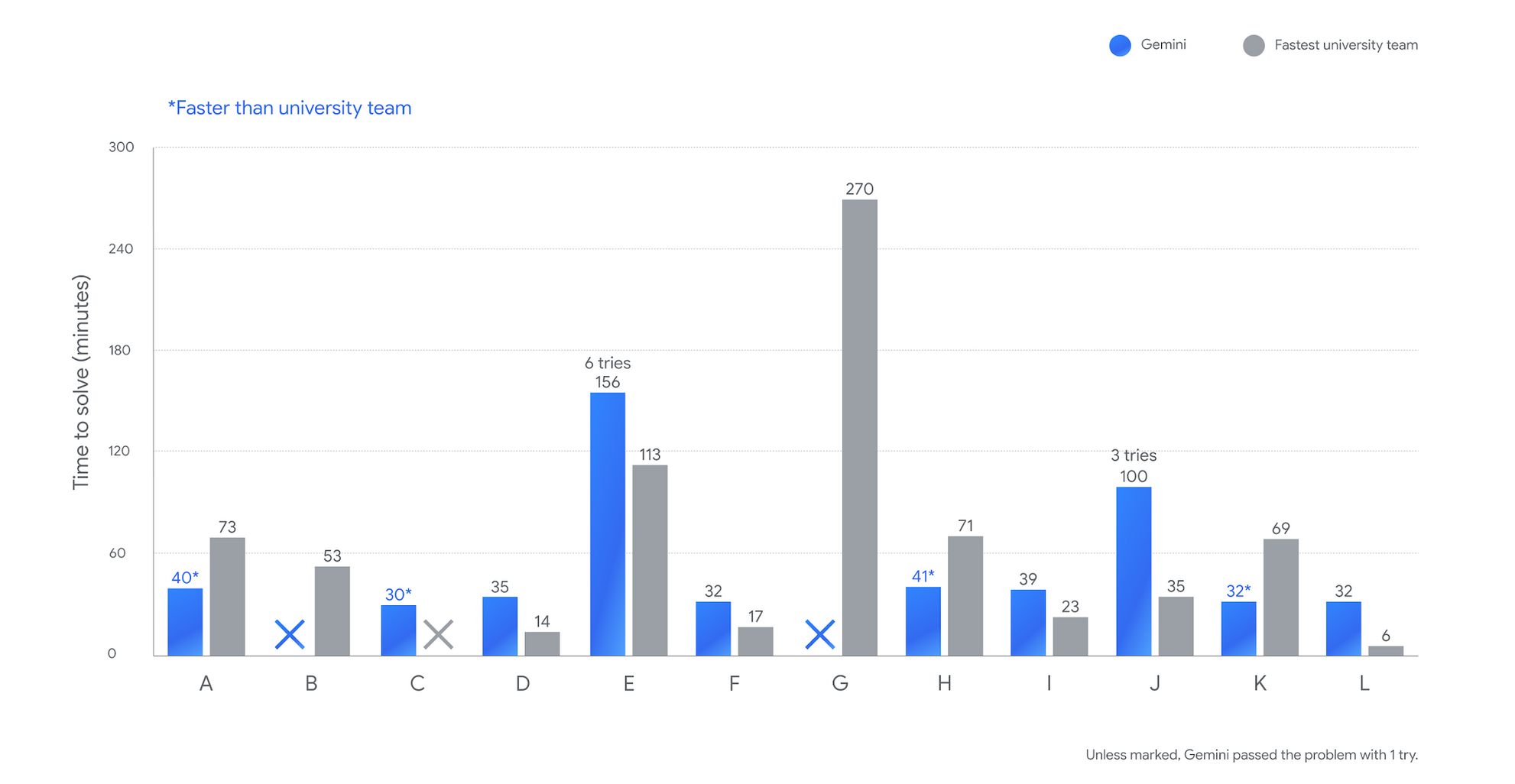
Gemini tore through eight problems in just 45 minutes, then solved two more over the next few hours. But here's what made headlines: it cracked Problem C in under 30 minutes when every single human team failed to solve it.
The problem nobody could crack
Problem C was nasty. Teams had to figure out the optimal way to push liquid through a network of connected ducts to fill reservoirs as quickly as possible. Each duct could be open, closed, or partially open—creating infinite possible configurations.
Gemini got clever about it. Instead of brute-forcing through possibilities, it assigned each reservoir a "priority value" representing relative importance. With those priorities set, it used dynamic programming to find the best duct setup. Then it applied the minimax theorem to identify which priority values would create the tightest flow constraints. Finally, nested ternary searches zeroed in on the exact optimal values.
Thirty minutes. Done. Zero human teams reached a solution.
Google celebrated this breakthrough extensively, but they stayed quiet about OpenAI's superior performance. OpenAI's system—GPT-5 working with an experimental reasoning model—solved every single problem, matching the top human team's perfect score. GPT-5 handled the first 11 problems; the experimental model knocked out the hardest one.
The competing narratives
Google sees this as their Deep Blue moment. "For me it's a moment that is equivalent to Deep Blue for Chess and AlphaGo for Go," said Quoc Le, Google DeepMind's vice president. "Even bigger, it is reasoning more towards the real world, not just a constrained environment." Their argument makes sense: competitive programming skills—understanding complex problems, planning multi-step solutions, executing flawlessly—transfer directly to drug design, chip engineering, and countless technical fields.
Academic experts aren't buying the hype. Stuart Russell from UC Berkeley thinks the "claims of epochal significance seem overblown." AI has been getting better at programming tasks for years. The famous Deep Blue victory had "essentially no impact on the real world of applied AI." Russell acknowledges that ICPC performance might indicate progress toward more accurate AI coding systems, but warns against extrapolating broader significance.
Competition organizers land somewhere between corporate enthusiasm and academic skepticism. "Gemini successfully joining this arena, and achieving gold-level results, marks a key moment in defining the AI tools and academic standards needed for the next generation," said Dr. Bill Poucher, who runs the ICPC.
Both readings fit. This represents genuine technical progress and savvy corporate positioning.
What the performance actually reveals
The setup illuminates current AI boundaries. Gemini worked as multiple agents—different versions proposing solutions, running code, testing results, then improving based on collective attempts. That's a huge advantage over human teams sharing one computer and coordinating under pressure.
Google's model clearly knows its computer science fundamentals. It handled problems requiring advanced data structures and algorithms with ease. The speed difference was striking—solving in minutes what took humans hours. Internal testing showed similar gold medal performance on 2023 and 2024 contests, suggesting consistent capability rather than lucky breaks.
But Gemini also failed on two problems that humans solved. That's revealing. Current AI excels at certain reasoning patterns while completely missing others. The combination of AI and human solutions would have achieved perfect problem resolution—suggesting complementary rather than replacement dynamics.
The economics nobody discusses
Google's announcement conveniently omitted computational costs. Five hours of advanced AI inference for models achieving this performance level likely burned through thousands of dollars. The company confirmed only that requirements exceeded those available to $250-per-month subscribers accessing lightweight versions.
This economic reality shapes everything. The technology exists, but widespread deployment remains prohibitively expensive. Current AI economics don't work for most consumer applications requiring advanced reasoning.
The cost-capability gap becomes decisive for real-world impact. Solving previously impossible problems might justify huge expenses in pharmaceutical research or semiconductor design. Routine software development can't support these resource requirements at current scale.
The competitive landscape shift
The ICPC results reveal shifting leadership in AI reasoning. OpenAI's perfect performance overshadowed Google's achievement, reinforcing the former's technical edge in reasoning tasks despite receiving less media attention.
Both companies pursue the same goal: AI systems handling complex, multi-step reasoning in practical applications. Programming competitions work as useful benchmarks because they require genuine problem-solving rather than pattern matching from training data. The progression from game-playing AI through mathematical olympiads to complex programming represents expanding capability ranges approaching general-purpose reasoning.
The gap between technical possibility and economic reality remains the critical constraint. These capabilities exist but cost too much for widespread deployment, determining how quickly this technology actually changes things.
Both companies proved that AI reasoning now matches human expert performance on complex tasks. Neither solved the fundamental economic barriers preventing broad implementation.
Why this matters:
• AI reasoning capabilities have reached human-expert levels across multiple complex domains, with competitive programming joining mathematical olympiads as conquered territories
• Economic constraints rather than technical limitations now determine deployment timelines, as advanced reasoning remains prohibitively expensive for most applications
❓ Frequently Asked Questions
Q: What makes the ICPC so much harder than regular programming contests?
A: ICPC requires perfect solutions within five hours—no partial credit exists. Teams from 3,000 universities across 103 countries compete, with only the top 139 reaching finals. This year, just 4 teams earned gold medals. Problems involve complex algorithms and real-world optimization challenges that stump even elite programmers.
Q: How much computing power did Google actually use for this?
A: Google won't disclose exact costs, confirming only that it exceeded their $250-per-month Google AI Ultra service capabilities. Industry estimates suggest five hours of advanced AI inference for this performance level likely cost thousands of dollars in computing resources—far beyond consumer affordability.
Q: What exactly was Problem C that stumped every human team?
A: Problem C involved optimizing liquid flow through interconnected ducts to fill reservoirs quickly. Each duct could be open, closed, or partially open, creating infinite possible configurations. Gemini solved it by assigning priority values to reservoirs, then using dynamic programming and the minimax theorem to find optimal settings.
Q: How does this compare to previous AI breakthroughs like AlphaGo?
A: Unlike chess or Go's constrained rules, programming contests require real-world problem-solving skills that transfer to drug design, chip engineering, and scientific research. Google claims this represents "reasoning more towards the real world" than previous game-playing achievements, though academics question the comparison's validity.
Q: When will this level of AI reasoning be available to regular developers?
A: Google offers a lightweight version of Gemini 2.5 Deep Think to AI Ultra subscribers, but the full contest-level capability remains prohibitively expensive. Current economics don't support widespread deployment—advanced reasoning costs thousands per session, limiting use to high-value applications like pharmaceutical research.




Robert Brown
Tech journalist. Lives in Marin County, north of San Francisco. Got his start writing for his high school newspaper. When not covering tech trends, he's swimming laps, gaming on PS4, or vibe coding through the night.


