On Monday, Moonshot AI put a familiar label on a less familiar move. Kimi K2.6 arrived as an open-source coding model, with a benchmark table, a Hugging Face page, a coding CLI, and the usual claims about lower cost and stronger software work. The useful number was not the self-reported 80.2 percent on SWE-Bench Verified. It was 300 agents and 4,000 coordinated steps.
That is the harder story behind the model card.
K2.6 is not mainly a bet that one open model can outscore Claude or GPT on every coding test. It is a bet that the next scarce product in AI coding will be the control room: the coordinator that assigns work, tracks failure, moves context between agents, and turns a model into a working software organization. Moonshot is still publishing weights. With K2.6, it is also teaching developers to look past weights toward orchestration.
That should make American labs nervous. It should also make enterprise buyers suspicious. Not because K2.6 proves open models have won. It does not. The more precise claim is sharper: open models are no longer trying to win only by being smaller, cheaper copies of closed systems. They are learning to run the work.
Key Takeaways
- Kimi K2.6 shifts open-source coding from model weights toward agent orchestration.
- Moonshot's benchmark claims need harness context before buyers treat them as settled.
- The control layer creates value, but provenance and versioning remain weak points.
- APEX suggests K2.6 narrowed the agent gap without overtaking top closed systems.
AI-generated summary, reviewed by an editor. More on our AI guidelines.
The benchmark table is bait
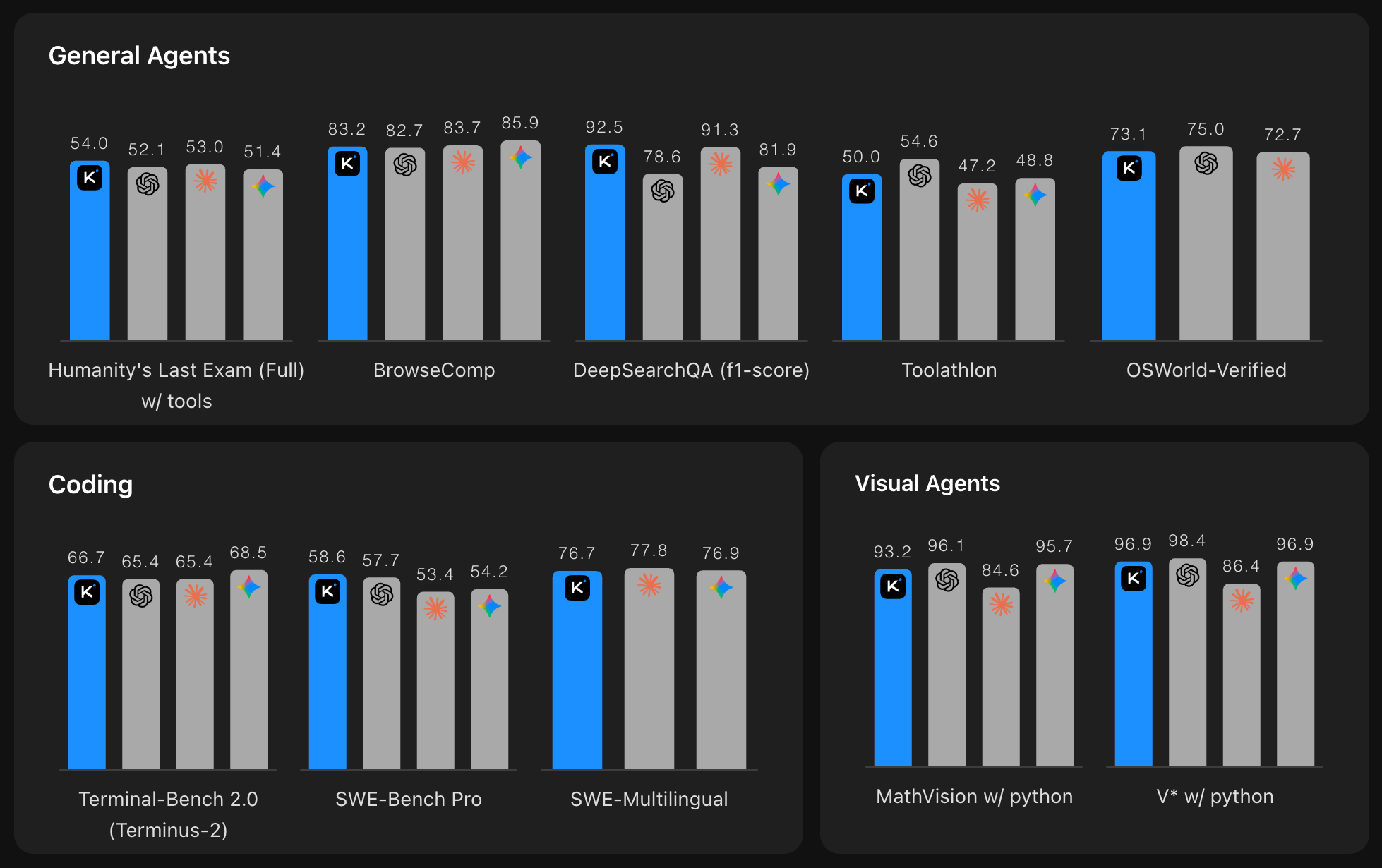
Moonshot's headline numbers are strong, but they need careful handling. The K2.6 model card lists a 1 trillion-parameter mixture-of-experts model with 32 billion active parameters per token, a 256K context window, 384 experts, a MoonViT vision encoder, and a Modified MIT license. The company reports 80.2 percent on SWE-Bench Verified, 58.6 on SWE-Bench Pro, 66.7 on Terminal-Bench 2.0, and 89.6 on LiveCodeBench v6.
The official SWE-bench leaderboard did not show K2.6 in the fetched results. It did show Kimi K2.5 scoring 70.8 percent under the mini-SWE-agent v2 harness, while Moonshot's own K2.5 table had reported 76.8 percent under its setup. That gap is not scandal. It is a warning label. Agent benchmarks measure the whole harness, not just the model. Change tools, retries, context handling, prompts, or timeout rules, and the scoreboard moves.
If you buy K2.6 only because the table says 80.2, you are buying the scoreboard. The real product is the machinery underneath it.
The control room got bigger
K2.5 already had the clue. It could spin up 100 sub-agents and push a run through 1,500 tool calls. K2.6 moves the ceiling to 300 agents and 4,000 steps. Not subtle.
That ratio matters more than another point on SWE-Bench. A single coding agent fails in familiar ways. It loses track of a task. It repeats itself. It burns context on old mistakes. It takes a problem that should branch and turns it into a long hallway. Moonshot calls that failure mode "serial collapse."
K2.6 is designed to fight that collapse by acting less like a genius and more like an operations manager. It breaks work into parallel pieces, assigns those pieces to specialized agents, watches for stalls, and reallocates work when an agent fails. In Moonshot's own examples, K2.6 optimizes a local Qwen3.5-0.8B inference stack over 12 hours and 4,000-plus tool calls, then overhauls an eight-year-old matching engine over 13 hours, 1,000-plus tool calls, and more than 4,000 changed lines.
Treat those as vendor claims, not independent proof. Still, the shape of the claim is telling. Moonshot is not saying only, "our model writes better functions." It is saying, "our system stays on task long enough to act like a team."
You can feel the market shifting there. The money in coding agents is moving from answer quality to task survival.
Open weights are becoming the entry ticket
The old open-source AI pitch was simple: take the weights, run them yourself, avoid the closed vendor. That pitch still matters for cost and data control. Kimi Code's product page lists paid plans from $15 to $159 per month. A BuildFastWithAI pricing comparison put Kimi API access at $0.60 per million input tokens and $2.50 per million output tokens, compared with Claude Sonnet 4.6 at $3 and $15. Treat that as a third-party price snapshot, not a procurement quote. Even then, the difference explains why finance teams feel relief.
But the K2.6 release also makes the old pitch feel incomplete. If the advantage is coordination, the weight file is only one component. You still need the CLI, routing logic, tool schema, permission model, sub-agent protocol, memory handling, and version controls that tell you which model actually ran.
That is where the open-source story gets uncomfortable. Moonshot can publish K2.6 and still own much of the practical control layer. Kimi Code's page uses the label "kimi-for-coding (powered by kimi-k2.6)." That may be clean for consumers, but it is weak for teams that need reproducible pipelines. If a production coding agent changes under a friendly label, your audit trail gets foggy.
Get The AI Control Room Brief
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
The control room is open enough to enter. It is not yet open enough to inspect.
Trust is the unpaid bill
Moonshot's technical rise now carries a trust tax. NIST's CAISI evaluation of Kimi K2 Thinking said it was the most capable model from a PRC-based developer at the time of release, while still behind leading U.S. models on agentic cyber and software engineering tasks. CAISI also found high Chinese-language censorship and weaker early Hugging Face adoption than DeepSeek R1 and gpt-oss.
Then Anthropic added a harsher charge. In February, Anthropic alleged that DeepSeek, Moonshot, and MiniMax generated more than 16 million Claude exchanges through roughly 24,000 fraudulent accounts. Anthropic said Moonshot accounted for more than 3.4 million exchanges targeting agentic reasoning, tool use, coding, data analysis, computer-use agents, and vision.
Those are allegations from a rival with policy interests. They still matter because K2.6 asks enterprises to trust long-running agents with code, credentials, logs, workflows, and internal documents. The more capable the control room becomes, the more sensitive the room becomes.
Cursor learned the same lesson from the other side. When Composer 2 turned out to have Kimi K2.5 underneath, the issue was not whether Kimi worked. It was whether users knew what they were trusting. Provenance becomes a security feature once an agent touches the codebase.
Moonshot has reason to feel pride. Buyers have reason to feel caution. Both can be true.
The rival answer is not a better chatbot
The best outside comparison is not another coding leaderboard. It is Artificial Analysis' APEX-Agents benchmark, which tests long-horizon work across files and professional tools. K2.5 scored 11.5 percent there. Moonshot's K2.6 table reports 27.9 percent, a large jump. But GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro still sit around 32 to 33 percent.
That is the whole story in one spread. K2.6 cuts the gap by changing the work pattern, yet it has not erased the gap. Closed labs still have stronger models, deeper enterprise trust, and more mature developer platforms. Moonshot has price, openness, and a sharper swarm story.
So the contest is not "open beats closed." It is "who owns the working system around the model?" OpenAI is pushing Codex deeper into professional workflows. Anthropic is turning Claude Code into a work surface. Google and GitHub are building layers that coordinate agents across repositories and tools. Moonshot is answering with a lower-cost, inspectable model and a control room that can spawn 300 workers.
If you run engineering, that is the choice now. Not model versus model. Manager versus manager.
The test is boring on purpose
K2.6 will not be judged by launch demos for long. The real test will be dull: can it keep agent runs reproducible, can teams pin versions, can failures degrade cleanly, can enterprises prove where code went, and can the swarm finish work without inventing confidence?
That last part matters most. A swarm does not remove supervision. It moves supervision up a level. You stop reviewing one answer and start reviewing a production process. More agents mean more places for error to hide.
K2.6 makes open-source AI coding feel less like a cheap clone and more like an operating model. That is the achievement. It also makes the risk clearer. Once the model starts assigning work, the question changes from whether it can write code to whether it can run a shop.
Moonshot did not just put new weights online. It invited developers into the control room. Now everyone has to ask who controls the switches.
Frequently Asked Questions
What is Kimi K2.6?
Kimi K2.6 is Moonshot AI's open-source multimodal coding and agent model. It is built around long-horizon coding, tool use, agent swarms, and Kimi Code workflows.
Why does the 300-agent number matter?
It shows Moonshot is selling coordination, not only raw model quality. K2.6 expands K2.5's 100-agent, 1,500-step setup to 300 agents and 4,000 coordinated steps.
Are K2.6's benchmark claims independently verified?
Not fully. Moonshot reports strong K2.6 results, but the fetched SWE-bench leaderboard did not list K2.6. Harness choices can move agent benchmark scores.
What is the trust issue around Moonshot?
Enterprises must weigh open weights and low cost against provenance, version pinning, censorship findings, and Anthropic's attributed distillation allegations against Moonshot.
How should teams evaluate Kimi K2.6?
They should run it on their own codebase, pin model versions where possible, review data flow, test failure handling, and compare total task cost, not only benchmark scores.
AI-generated summary, reviewed by an editor. More on our AI guidelines.



Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai