


💡 TL;DR - The 30 Seconds Version
🔍 First comprehensive survey maps 283 LLM benchmarks and finds systematic flaws undermining AI evaluation across three critical areas.
💀 Data contamination inflates performance scores as training datasets overlap with test sets, making progress claims potentially meaningless.
🌍 Cultural and linguistic bias in most benchmarks creates unfair assessments that favor English and Western contexts over global populations.
⚙️ Current evaluation focuses only on final outputs, ignoring reasoning processes crucial for reliability in high-stakes applications.
🤖 "LLM-as-judge" evaluation paradigm risks creating AI monoculture where models converge on house styles rather than robust competence.
🚨 Flawed evaluation frameworks threaten to deploy AI systems whose true capabilities remain unknown, particularly in critical applications.
A wave of AI progress claims runs into a measurement wall. A new first survey of 283 benchmarks finds that the yardsticks used to judge large language models are riddled with data contamination, cultural bias, and output-only scoring that ignores how answers are produced.
What’s actually new
The paper is the first systematic taxonomy of the LLM evaluation ecosystem. It groups benchmarks into three tiers: general capabilities (linguistic core, knowledge, reasoning), domain-specific (from law and medicine to software engineering), and target-specific (safety, robustness, agent skills). That structure matters because it exposes gaps, not just a list of scores. It’s a map.
The authors also document a shift from single-metric tests to multi-dimensional evaluations and “LLM-as-judge” setups, where a strong model grades another model’s open-ended output. That makes large-scale evaluation cheaper and faster. It also risks locking the field to the preferences and quirks of the graders.
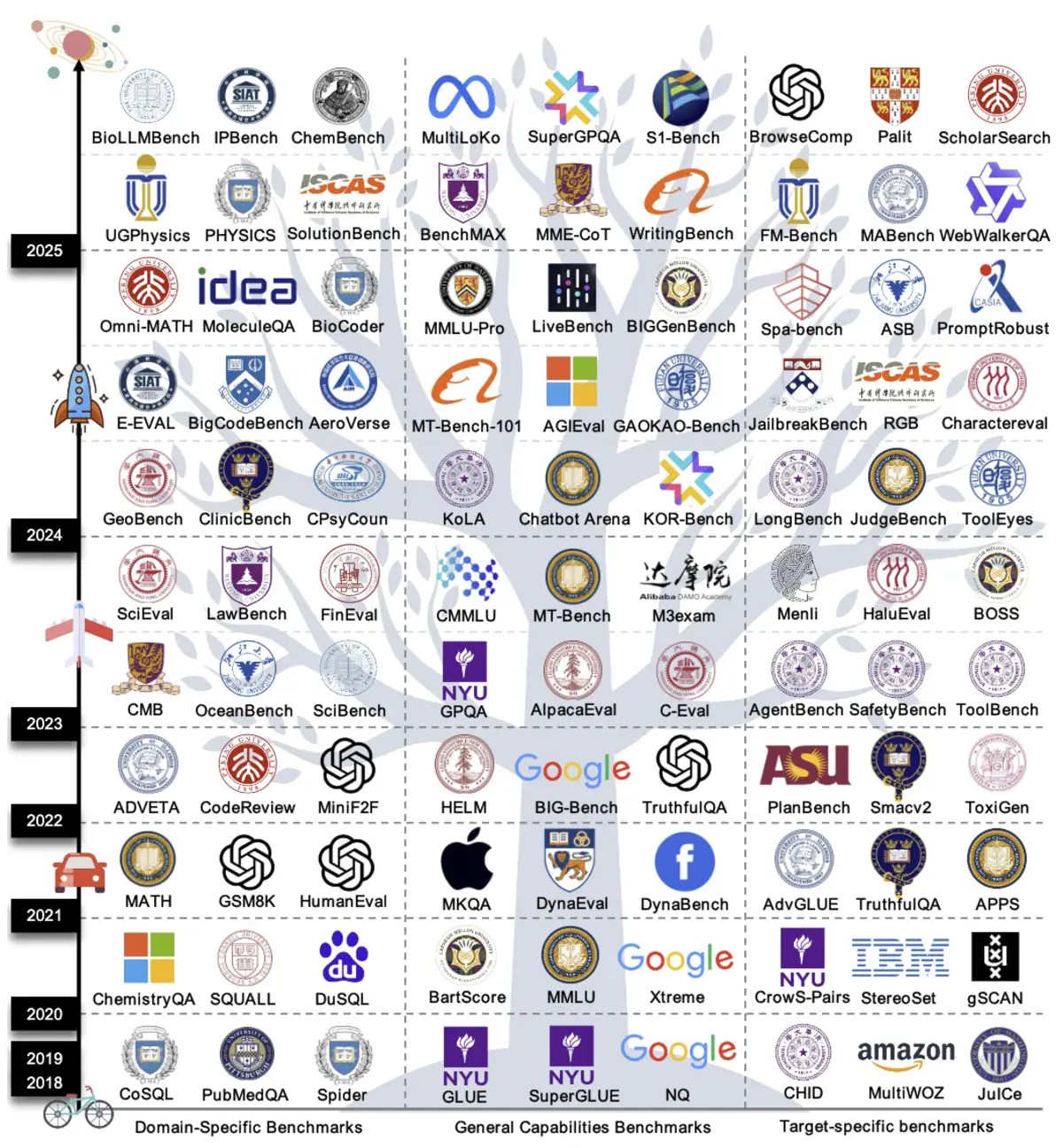
The contamination trap
The most acute problem is benchmark leakage. As training corpora balloon, overlap with test sets becomes likely, sometimes certain. Gains on familiar benchmarks can reflect recall, not reasoning. That undercuts trend lines many labs treat as proof of steady capability growth.
Countermeasures exist but are fragile. “Contamination-resistant” suites such as LiveCodeBench continuously pull fresh coding tasks; “Google-proof” sets like GPQA are written by domain experts to evade simple retrieval. Useful, yes. But once a dataset is public, it’s a sitting duck for the next training run. The treadmill never stops.
Cultural bias isn’t a footnote
Most widely used benchmarks are built in English and reflect Western reference frames. That bias shows up in idioms, assumptions, knowledge lists, and even in how “good” answers are scored. The result is a skewed picture of what models can do for the world rather than for one linguistic market.
This isn’t just about fairness. It’s about validity. A model that looks competent on Western-centric tests can stumble in non-Western settings because the evaluation never asked the right questions in the first place. That is a product risk.
Outcomes without process
Today’s leaderboards mostly evaluate the final answer. For complex tasks, the path matters as much as the destination. Did the model reason step-by-step, check its work, and handle uncertainty? Or did it guess confidently and get lucky? Most benchmarks can’t tell.
Process-aware evaluation is starting to appear: verifying intermediate steps, scoring consistency across related tasks, and quantifying uncertainty and calibration. These are harder to automate and standardize, yet they’re the tests that map to reliability in production. Trust requires a trail.
The LLM-as-judge monoculture risk
Using models to grade other models has momentum. It reduces cost, scales to open-ended outputs, and avoids fatigued human raters. The danger is monoculture: if one or two frontier models set the taste for “good writing” or “good reasoning,” systems trained to please those judges may converge on a house style rather than robust competence.
Mitigations are emerging: ensembles of judges, rubric-based prompts, adversarial checks, and periodic audits with human experts. But none of that removes the need for transparent, falsifiable criteria that don’t depend on a single model’s preferences. Diversity in judges is a feature, not a bug.
What buyers and builders should do now
Treat legacy leaderboards as smoke alarms, not medical diagnostics. They can tell you something is off, not exactly what. For procurement, insist on task-specific, contamination-checked evaluations using your own data distributions and languages. Verify not just answers but reasoning traces when decisions carry real-world consequences. Write this into contracts.
For model and product teams, invest in dynamic, living benchmarks tied to deployment contexts. Rotate data, procedurally generate variants, and track process metrics like step validity and error recovery. Measure out-of-distribution drift. In short, benchmark your system, not just your model.
What a better playbook looks like
The authors push three directions. First, dynamic and adaptive benchmarks that evolve with models and resist leakage through continual refresh, programmatic generation, and interactive tasks. Second, process-oriented scoring that verifies intermediate steps, uncertainty calibration, and cross-task consistency. Third, culturally inclusive, multilingual evaluation that balances coverage across languages and knowledge systems, and tests translation-invariant criteria where possible. Ambitious, but necessary.
Finally, move from scattered tests to integrated evaluation ecosystems. Single scores hide failure modes. Portfolios of tasks, with clear provenance and refresh policies, surface them. That’s how the field grows out of leaderboard theater.
Limits and caveats
This is a survey, not a new benchmark. It relies on public documentation and can only catalog what the community has published. Some industry evaluations are private and may already implement pieces of this agenda. But the direction of travel is clear. The status quo won’t hold.
Why this matters
- Shipping models judged by contaminated or culturally narrow tests is a business and safety risk; the wrong benchmark can green-light the wrong system.
- Process-aware, dynamic, and inclusive evaluation is the difference between leaderboard gains and dependable performance in the real world.
❓ Frequently Asked Questions
Q: What exactly is data contamination in AI benchmarks?
A: Data contamination occurs when test questions appear in training datasets, allowing models to memorize answers rather than demonstrate reasoning. As training corpora expand beyond 10 trillion tokens, overlap with benchmark datasets becomes increasingly likely. Models may show inflated performance on familiar tests while struggling with genuinely novel problems.
Q: How can organizations detect if a benchmark is contaminated?
A: Contamination detection requires analyzing training data overlap, monitoring for memorization indicators, and checking for anomalous performance spikes on specific datasets. However, these methods remain computationally expensive and imperfect. The survey recommends using "contamination-resistant" benchmarks like LiveCodeBench that continuously refresh with new problems.
Q: What does "LLM-as-judge" evaluation actually mean?
A: LLM-as-judge uses advanced AI models to grade other models' outputs, particularly for open-ended tasks where human evaluation is expensive. This approach scales evaluation but risks creating monoculture where models converge on the judging model's stylistic preferences rather than developing diverse, robust capabilities.
Q: How do you evaluate reasoning process instead of just final answers?
A: Process evaluation involves verifying intermediate steps, checking consistency across related tasks, and quantifying uncertainty calibration. This includes tracking whether models show their work, correct errors mid-process, and maintain logical coherence. Such evaluation is harder to automate but crucial for deployment in high-stakes applications.
Q: What should companies do differently when evaluating AI for their specific use cases?
A: Companies should demand task-specific, contamination-checked evaluations using their own data distributions and languages. Rather than relying on public leaderboards, conduct internal testing with domain-specific problems, verify reasoning processes for critical decisions, and measure performance across different cultural and linguistic contexts relevant to their markets.





