


French AI company Mistral unveiled a new OCR API on Thursday. The tool transforms PDFs into text files optimized for AI processing.
Large language models work best with clean text data. Mistral OCR addresses this need by converting complex documents into machine-digestible formats. The timing aligns with growing demand for efficient document processing in AI workflows.
Markdown Magic Trumps Plain Text
Unlike standard OCR tools, Mistral's offering handles multimodal content. It detects images and illustrations within text, creates bounding boxes around them, and includes these elements in the output. This preserves the visual context that other tools might strip away.
The API outputs formatted Markdown rather than unstructured text. Markdown has become an essential format in AI development. It allows for headers, links, and other formatting elements while maintaining simplicity. AI assistants like ChatGPT and Mistral's Le Chat generate Markdown routinely, which their interfaces convert to rich text.
Benchmarks Leave Competitors In The Dust
"Over the years, organizations have accumulated numerous documents, often in PDF or slide formats, which are inaccessible to LLMs, particularly RAG systems," said Guillaume Lample, Mistral's co-founder and chief science officer. "With Mistral OCR, our customers can now convert rich and complex documents into readable content in all languages."
Lample added: "This is a crucial step toward the widespread adoption of AI assistants in companies that need to simplify access to their vast internal documentation."
Mistral OCR processes approximately 90% of organizational data trapped in document formats. The company positions the tool as ideal for Retrieval Augmented Generation (RAG) systems consuming multimodal documents like slides or intricate PDFs.
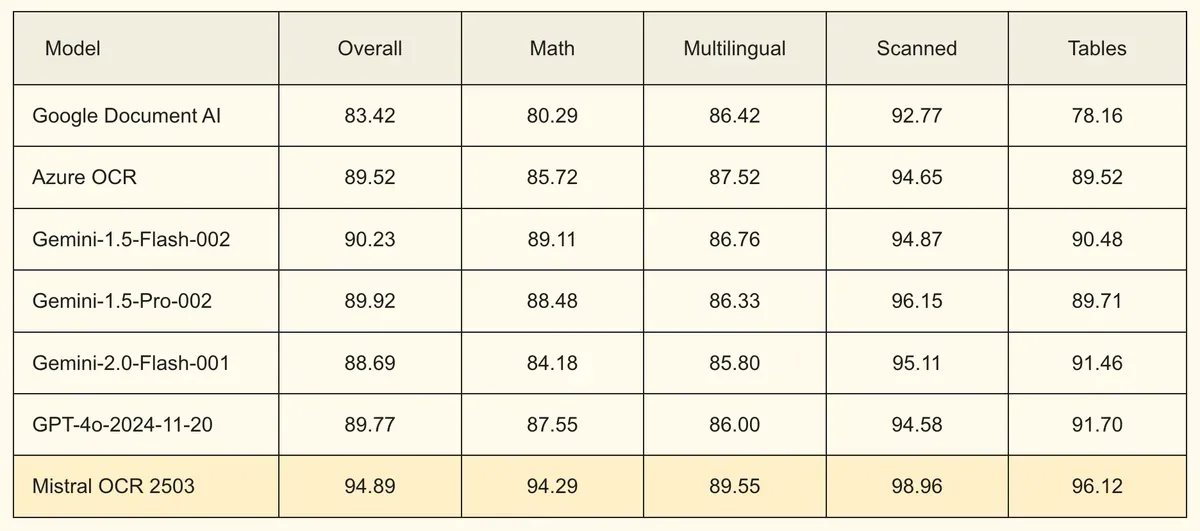
The technology promises impressive benchmarks. Mistral claims 94.89% overall accuracy, outperforming competitors from Google (83.42%), Azure (89.52%), and Gemini models (topping out at 90.23%). It particularly excels in mathematics (94.29%), multilingual capabilities (89.55%), scanned documents (98.96%), and table recognition (96.12%).
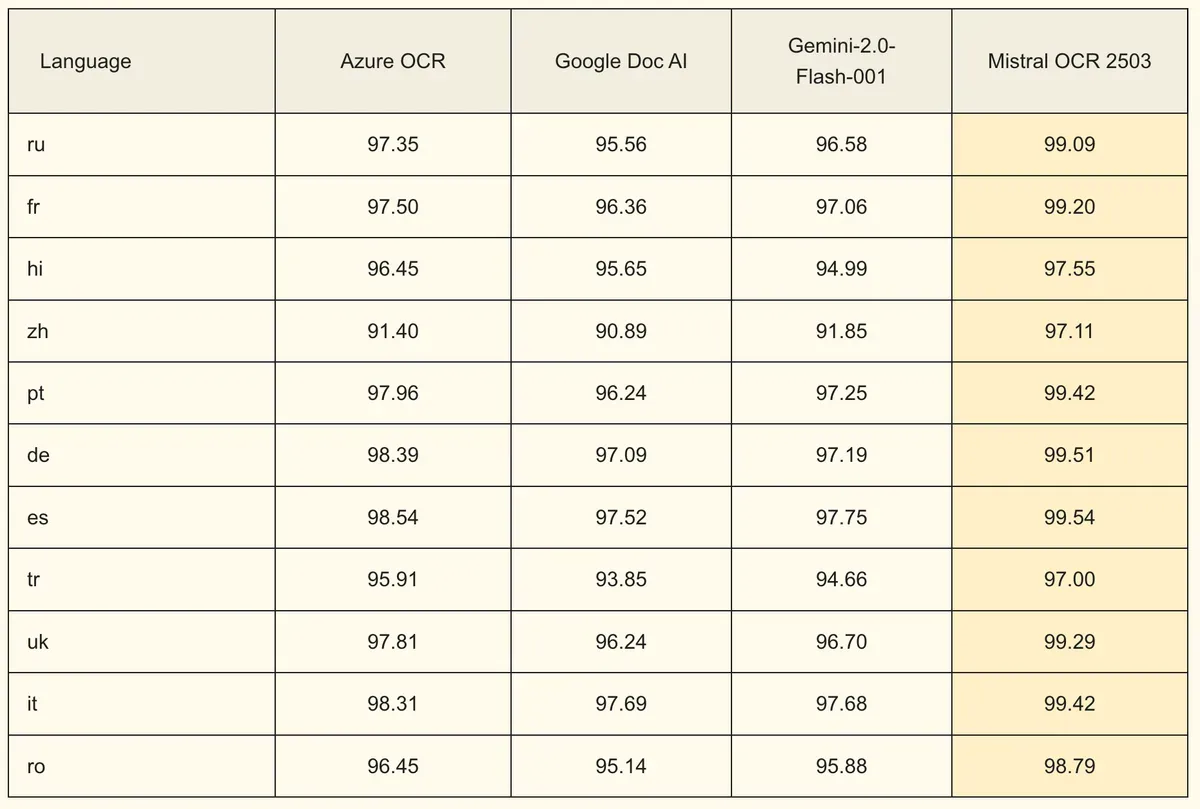
Multilingual Monster Devours Documents
Speed stands as another selling point. The model processes up to 2000 pages per minute on a single node. This performance makes sense given its specialized focus compared to multimodal LLMs like GPT-4o that offer OCR alongside many other capabilities.
Mistral already deploys this technology in Le Chat, its AI assistant. When users upload PDFs, Mistral OCR processes the document before the LLM interprets the content. The API launched on Mistral's developer platform "la Plateforme" and will expand to cloud and inference partners soon.
The pricing structure offers 1000 pages per dollar, with batch processing doubling that efficiency. For security-conscious organizations, selective self-hosting options exist for sensitive information.
Organizations have already found diverse applications. Research institutions digitize scientific papers to accelerate collaboration. Cultural heritage organizations preserve historical documents. Law firms might use it to quickly process large document volumes. Customer service departments transform manuals into searchable knowledge.
The API's multilingual capabilities support thousands of scripts, fonts, and languages across all continents. From Russian to Hindi, Portuguese to Chinese, the model maintains high accuracy across language recognition benchmarks.
From Research Papers To Legal Briefs: Real-World Impact
Mistral OCR also introduces "doc-as-prompt" functionality. This allows users to extract specific information from documents and format it as structured outputs like JSON. Such capability creates opportunities for chaining outputs into downstream function calls and building document-aware AI agents.
The technology is available today through Mistral's Le Chat for free trials. Developers can access the API on la Plateforme. Mistral promises ongoing improvements and selective on-premises deployment for organizations with specialized requirements.
Why this matters:
- Organizations can finally unlock the 90% of their data trapped in documents, converting complex PDFs into AI-ready formats that preserve both text and visual elements
- RAG systems gain a powerful new tool for ingesting multimodal documents, potentially transforming how industries like law, research, and customer service handle their vast document archives
Read on, my dear:






