Seven months ago, OpenAI launched GPT-5 with the promise of a smarter machine. Sam Altman compared the development to the Manhattan Project. Early testers shrugged. Benchmarks improved by single digits. All that hype, months of leaks and breathless previews, ran headfirst into a reality made of incremental gains.
Thursday brought GPT-5.4. No one called it a breakthrough this time. No Manhattan Project comparisons. The blog post opened with spreadsheets. Spreadsheets and presentations and documents. The most capable frontier model in the world, and its opening pitch was Excel.
That shift tells you everything about where OpenAI thinks the money is. Not in making models think harder. In making them work longer.
The Breakdown
- GPT-5.4's reasoning benchmarks barely moved while professional work scores jumped from 70.9% to 83.0% in three months
- Every major feature targets autonomous labor: computer use, 1M context, memory compaction, tool search
- Input token pricing rose 43% to $2.50 per million as OpenAI chases enterprise revenue over consumer growth
- Microsoft added Claude to Copilot 365 after it outperformed OpenAI on spreadsheet and presentation tasks
The intelligence ceiling and the labor floor
GPT-5.4's benchmark card tells the story if you know where to look. The academic results barely moved. GPQA Diamond went from 92.4% to 92.8%. SWE-Bench Pro crept from 55.6% to 57.7%. These are rounding errors dressed up as progress. If you've been tracking the slowdown since last summer, none of this surprises you.
But the professional work numbers tell a different story. GDPval, which measures whether AI can match human professionals across 44 occupations, jumped from 70.9% to 83.0% in three months. OSWorld, testing whether models can actually operate a desktop computer, leaped from 47.3% to 75.0%, surpassing human performance at 72.4%. Investment banking spreadsheet tasks went from 68.4% to 87.3%.
Call them what they are. Labor gains. The model got barely smarter but dramatically more useful, and that distinction changes what OpenAI is actually selling.
The plumbing tells the story
Every major feature in GPT-5.4 is infrastructure for autonomous work. Not one of them makes the model reason better in isolation.
Computer use lets agents read screenshots and press keys. One million tokens of context means an agent can remember what it's been doing across hours of work, not minutes. Native compaction goes further. The model taught itself to compress its own memory mid-run, shedding weight to keep operating even when the task stretches past what the context window should allow. And tool search solves the problem of scale, letting agents pull the right tool definitions from a library of thousands at runtime instead of loading everything upfront and choking on token costs.
On the MCP Atlas benchmark, which tests how well agents handle real tool ecosystems with 36 servers enabled, putting all tools behind search cut total token usage by 47% while matching the accuracy of loading every schema into context. That's not a marginal improvement. That's the difference between an agent that costs too much to deploy and one that actually pencils out.
Every feature solves the same problem. How do you keep an AI working for hours without a human hovering over it? OpenAI didn't build a better brain. They built better hands, better memory, and a longer attention span. The plumbing for a digital employee.
Join 10,000+ AI professionals
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
When OpenAI pushed GPT-5-Codex into the coding market last September, the pitch was still about code quality. GPT-5.4 absorbed Codex's coding strengths and wrapped them in something bigger. The model now writes code specifically to operate computers, chaining Playwright scripts to click through browser interfaces and fill out forms. That's not a coding tool anymore. It's a worker.
Why the enterprise pivot is existential
OpenAI is nervous, and the pricing makes it obvious. Input tokens jumped 43% to $2.50 per million. Output tokens rose from $14 to $15. The company's argument is that token efficiency offsets the increase, that GPT-5.4 solves problems in fewer steps. Maybe. But you don't raise prices on a product people are already walking away from unless you're chasing a different customer entirely.
The consumer story has turned ugly. Reports of 2.5 million users pledging to quit ChatGPT circulated the same week as the launch. OpenAI's response was telling. They released GPT-5.3 Instant on Tuesday, a model designed to "reduce the cringe" in everyday conversations, and then announced GPT-5.4 the same day. One model to stop the bleeding. Another to chase the revenue.
And the enterprise customer they need most already wandered. Microsoft brought Anthropic's Claude into Copilot 365 last September. Internal testing, according to multiple reports, showed Claude beating OpenAI on the exact tasks GPT-5.4 now targets, spreadsheets and presentations. Losses like that don't just sting. They rewrite roadmaps. OpenAI's response was a ChatGPT for Excel add-in, launched alongside GPT-5.4. Damage control wearing a product announcement's clothes.
The benchmark that matters most
GDPval deserves a closer look, because it's the benchmark OpenAI has restructured its entire product around. The test measures AI performance on real tasks across nine industries contributing the most to US GDP. Manufacturing engineers designing cable spool jigs. Investment analysts building financial models. Lawyers structuring transactional analysis. Graders are human professionals sitting with the output, not knowing whether they're evaluating AI or work from a peer down the hall.
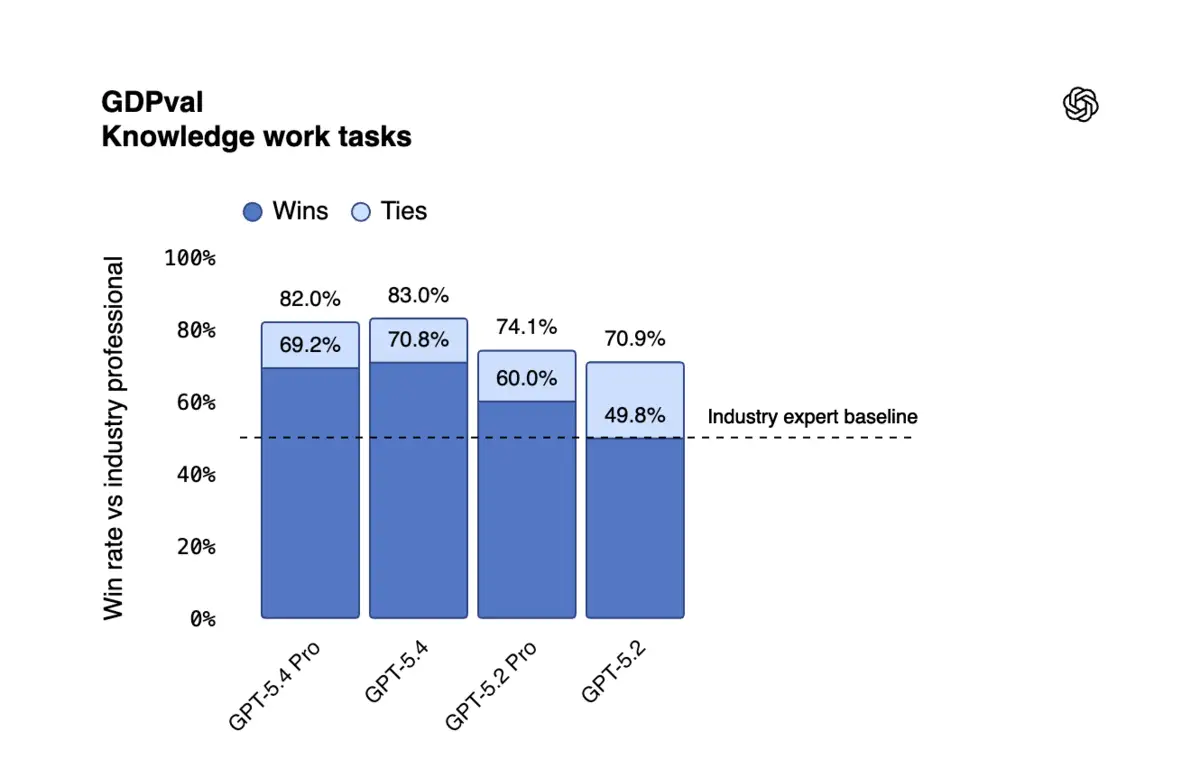
In November, GPT-5.1 scored 38.8%. December brought GPT-5.2 at 70.9%. Now GPT-5.4 hits 83.0%. That trajectory is almost vertical, and it's happening while raw reasoning benchmarks flatline.
OpenAI figured out something that should make every enterprise software company anxious. You don't need a smarter model to replace a junior analyst. You need a model that can open Excel, build a financial model, format it correctly, and not hallucinate the numbers. Individual factual claims in GPT-5.4 are 33% less likely to be wrong than in GPT-5.2, according to OpenAI's own testing. Full responses carry 18% fewer errors. For a company billing $25 billion in annualized revenue while burning through $1.4 trillion in data center commitments, "good enough to replace a first-year analyst" beats "occasionally brilliant but unreliable" every time.
The race nobody expected
The irony is thick. OpenAI spent years positioning itself as the company pushing toward artificial general intelligence. The research lab that would build the mind of the future. What it actually built with GPT-5.4 is closer to a very expensive temp agency.
And it's working. Mercor's CEO called GPT-5.4 "the best model we've ever tried" on their professional services benchmark. Harvey, the legal AI company, reported 91% on their BigLaw evaluation. Mainstay saw 95% first-attempt success rates across 30,000 property tax portals, three times faster than previous models while using 70% fewer tokens.
None of those testimonials mention intelligence. Speed, accuracy, cost. The vocabulary has changed, and nobody in the room seems to miss the old words.
You can see where this leads. The next GPT won't be sold on how well it reasons about philosophy or scores on math olympiads. It'll be sold on how many spreadsheets it can build per hour, how many browser tabs it can manage simultaneously, how long it can run before it needs a human to check its work. The intelligence ceiling is real, and OpenAI found the trapdoor. Stop climbing. Start digging. Build the model that works, not the model that thinks.
The plumbing company just became the most valuable AI lab on earth. Whether that's a pivot or a surrender depends on what you thought they were building in the first place.
Frequently Asked Questions
What is GDPval and why does it matter for GPT-5.4?
GDPval tests whether AI can match human professionals across 44 occupations in nine GDP-contributing industries. GPT-5.4 scores 83.0%, up from 70.9% three months ago. OpenAI has restructured its product strategy around this benchmark.
Did GPT-5.4 actually get smarter?
Barely. Academic reasoning benchmarks moved by fractions: GPQA Diamond went from 92.4% to 92.8%, SWE-Bench Pro from 55.6% to 57.7%. The gains are in professional task execution, not raw intelligence.
Why did OpenAI raise API prices with GPT-5.4?
Input tokens jumped 43% to $2.50 per million. OpenAI argues the model uses fewer tokens per task, offsetting the increase. The price hike signals a pivot toward enterprise customers willing to pay more for agent-grade performance.
What is computer use in GPT-5.4?
GPT-5.4 can read screenshots and issue keyboard and mouse commands to operate desktop software. It scores 75.0% on OSWorld, surpassing human performance at 72.4%. It's the first OpenAI production model with this built in.
How does tool search reduce costs for AI agents?
Instead of loading every tool definition into context upfront, GPT-5.4 defers loading until runtime. On the MCP Atlas benchmark with 36 servers, this cut token usage by 47% while matching accuracy. It makes large-scale agent deployment economically viable.




Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai