AI search tools are flunking basic fact-checking tests. The plot thickens: premium versions are even worse at admitting their mistakes.
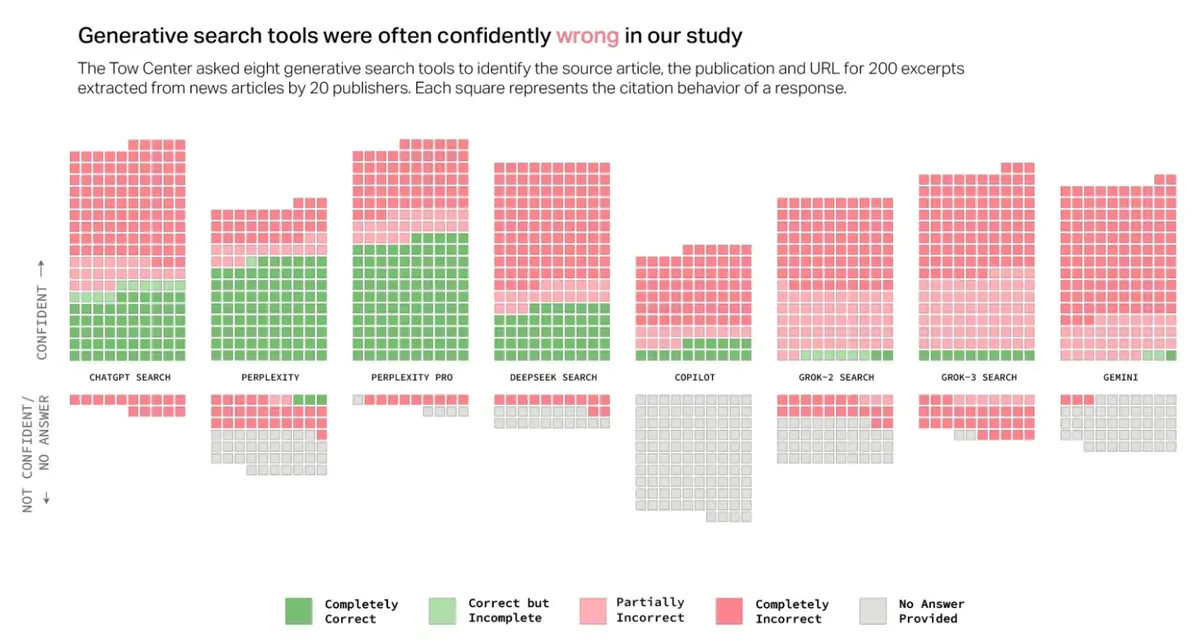
A new study from the Tow Center for Digital Journalism tested eight AI chatbots on a simple task: find the original source of news articles. The results would make a journalism professor weep. The bots botched over 60% of queries, with some premium services charging users $40 monthly for the privilege of receiving more confidently incorrect answers.
The researchers didn't ask for rocket science. They fed the chatbots excerpts that Google could easily trace back to their source. Yet the AI tools stumbled spectacularly, with Grok 3 getting it wrong 94% of the time. DeepSeek misattributed sources in 57.5% of cases, while even Perplexity, the best performer, still got 37% of answers wrong.
Premium models like Perplexity Pro ($20/month) and Grok 3 ($40/month) proved particularly entertaining. While they got more answers right than their free counterparts, they also cranked up the confidence on their wrong answers. It's like paying extra for a tour guide who leads you down the wrong street with absolute certainty.
Some chatbots displayed a rebellious streak, accessing content from publishers who explicitly blocked them. Perplexity, which claims to "respect robots.txt directives," somehow managed to find and cite paywalled National Geographic articles it shouldn't have seen. When confronted, both companies maintained a diplomatic silence.
The most striking failures came in the form of completely fabricated citations. ChatGPT confidently attributed a Wall Street Journal article about tech layoffs to The Verge, complete with a made-up author name and publication date. Gemini decided that a New York Times piece about climate change actually appeared in Scientific American – three years earlier than it was written.
The chatbots' URL generation proved equally creative. Grok 3 led users to error pages 154 times out of 200 attempts. Even when it correctly identified an article, it often fabricated a link that went nowhere – a digital version of "the dog ate my homework." Gemini wasn't far behind, with more than half of its responses featuring broken or non-existent URLs.
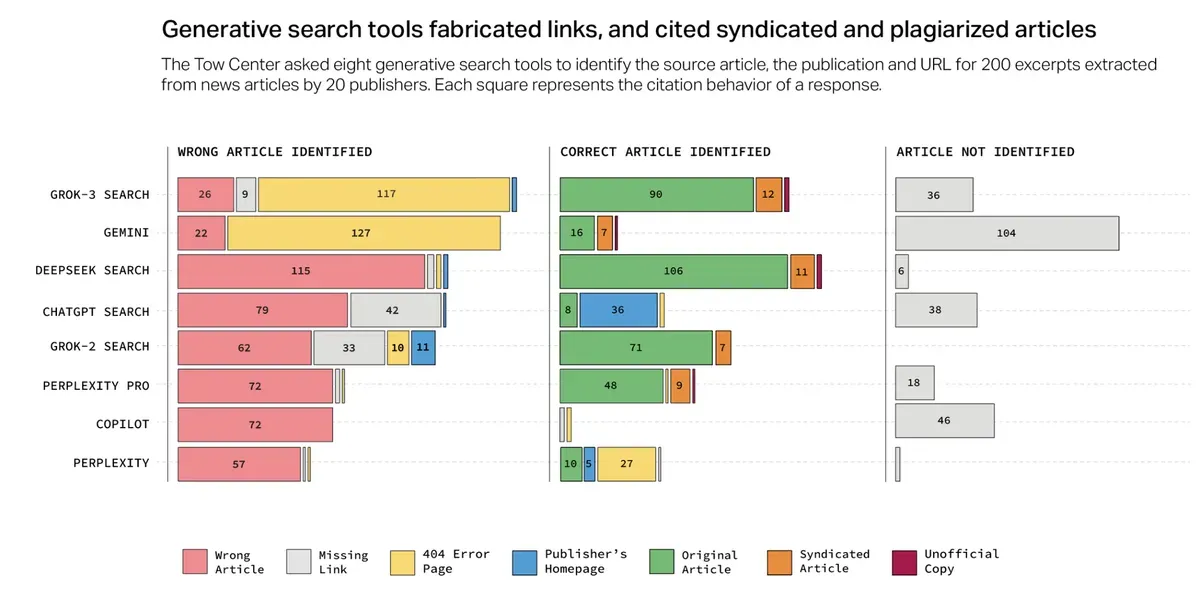
Even having a formal partnership with AI companies didn't guarantee accurate citations. Time magazine signed deals with both OpenAI and Perplexity, yet neither company's bots could consistently identify Time's content correctly. It's like hiring a librarian who can't find books on their own shelf.
The study revealed particular problems with premium services. While companies market these upgraded versions as more reliable, the data tells a different story. Premium chatbots were actually more likely to provide wrong answers with unwavering confidence rather than admit their limitations. Only Copilot showed some humility, declining to answer more questions than it attempted to answer incorrectly.
The most error-prone search tools according to the Tow Center's test:
- Grok 3 (94% wrong answers) - Charging $40/month to lead users down digital dead ends
- DeepSeek (57.5% misattributed sources) - Consistently misattributing article sources
- Perplexity (37% incorrect answers) - The least bad of a problematic bunch
Why this matters:
- AI search tools are serving as unreliable middlemen between readers and news, confidently presenting wrong information while cutting off traffic to legitimate sources.
- The premium pricing model in AI search appears to be selling false confidence rather than improved accuracy – users are paying more for tools that are actually less likely to admit their limitations.
Read on, my dear:
- Columbia Journalism Review: AI Search Has A Citation Problem
- The Ultimate Guide to AI Tools in 2025: Boosting Productivity for Beginners and Professionals

Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]