A team from UC Santa Barbara, MIT-IBM Watson AI Lab, and Rutgers University found that AI models hit a sweet spot in size - after which their reasoning abilities decline. Think of it like a brain that's grown too big for its own good.
The discovery emerged from testing AI models on knowledge graphs - simplified networks of facts and relationships that mimic how we organize information. The researchers trained various AI models to complete missing connections in these knowledge webs, essentially asking them to connect the dots using logic.
What they found upends conventional wisdom. While larger models initially performed better at reasoning tasks, their performance eventually peaked and then declined. The researchers call this the "U-shaped curve" - a phenomenon where throwing more computing power at the problem actually makes things worse.
This phenomenon was observed in synthetic environments designed to mimic real-world knowledge, not in full-scale natural language models like GPT or Gemini. Overparameterization causes models to focus on memorization rather than reasoning. The models store information but fail to make logical connections between pieces of knowledge.
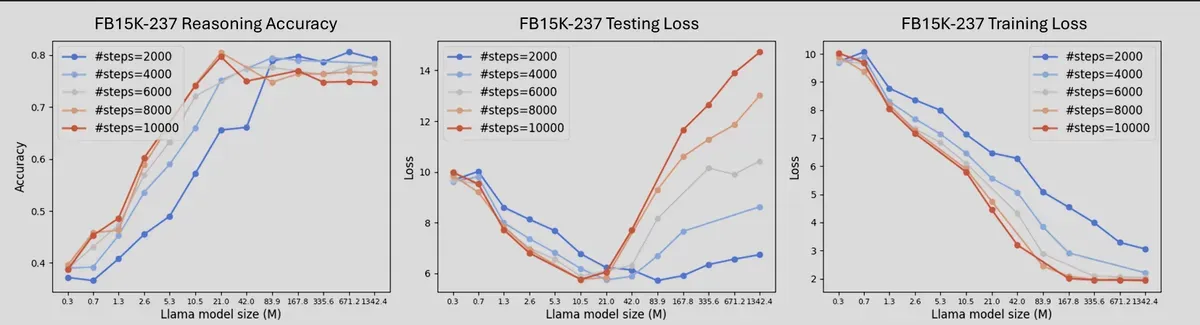
The study identified a sweet spot - an optimal size where models reason most effectively. This optimal size isn't fixed but depends on the complexity of the knowledge being processed. The more intricate the web of information, the larger the ideal model size needs to be.
The researchers developed a new way to measure this complexity, called "graph search entropy." For every bit of increased complexity in the knowledge graph, they found that models needed about 124 additional parameters to reason effectively. This precise relationship could help companies right-size their AI models for specific tasks.
These findings have major implications for the AI industry's "bigger is better" mindset. Companies like OpenAI and Google have been racing to build ever-larger language models, with parameters numbering in the trillions. But this research suggests that some of these massive models might actually be too big for their own good - at least when it comes to reasoning tasks.
The study also revealed that models can only reliably process about 0.008 bits of information per parameter when reasoning - far less than their capacity for simple memorization. This suggests that reasoning is fundamentally more demanding than just storing and recalling information.
However, the researchers caution that their findings come from simplified test environments. Real-world language models deal with messier, more complex data. Still, the principle that oversized models can hamper reasoning might hold true in the wild.
The implications extend beyond artificial intelligence. This research offers insights into the nature of reasoning itself and the relationship between memory and logical thinking. Just as human minds need to balance memorization with analytical skills, AI systems appear to require a similar equilibrium.
Looking ahead, these findings could reshape how we approach AI development. Instead of simply scaling up model size, developers might focus on finding the optimal size for specific reasoning tasks. This could lead to more efficient, focused AI systems that reason better with fewer resources.
Why this matters:
- The AI industry's "bigger is better" approach may be hitting diminishing returns. This research suggests we need smarter, not just larger, models.
- Companies could save millions in computing costs by right-sizing their AI models instead of defaulting to the largest possible size. A precisely tuned smaller model might outperform its oversized cousins at reasoning tasks.
Read on, my dear:

Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai