


💡 TL;DR - The 30 Seconds Version
🧠 UC Berkeley researchers created INTUITOR, an AI training method that lets models learn without answer keys by using their own confidence as feedback
📊 Models trained on just 7,500 math problems matched traditional methods but showed 65% better performance when transferring skills to coding tasks
🔄 Self-taught AI spontaneously developed new behaviors like explaining reasoning before solving problems—something nobody programmed it to do
💰 The approach eliminates expensive human feedback and works in domains where correct answers can't be verified, cutting training costs dramatically
⚡ Online self-assessment prevents models from becoming overconfident in wrong approaches, solving a key challenge in unsupervised learning
🚀 This opens doors for AI to tackle problems beyond human ability to verify—from advanced science to entirely new fields of knowledge
Picture teaching a child math by only telling them whether their final answer is right or wrong. That's essentially how AI companies train today's most advanced AI systems. Now researchers from UC Berkeley have found a way for AI to learn complex reasoning without needing any answer key at all.
The team's new method, called INTUITOR, lets AI models improve by paying attention to their own confidence levels. When the model feels certain about its reasoning, it reinforces that approach. When it's uncertain, it tries different strategies.
This matters because current AI training hits two major walls. Human feedback is expensive and often biased. Automated checking only works in narrow domains like math, where answers are clearly right or wrong. But what happens when AI needs to learn tasks where there's no simple answer key?
The confidence signal
"Can LLMs enhance their reasoning abilities by relying solely on intrinsic, self-generated signals, without recourse to external verifiers or domain-specific ground truth?" the researchers asked. Their experiments suggest yes.
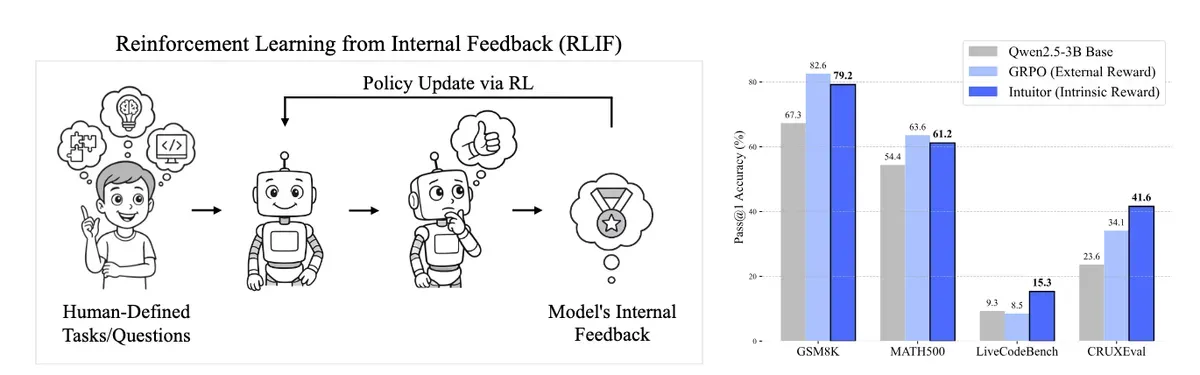
The Berkeley team tested INTUITOR by training AI models on mathematical problems. Despite never being told which answers were correct, the models matched the performance of traditionally trained systems. More surprisingly, these self-taught models transferred their skills better to unrelated tasks like writing code.
The key insight is that AI models already contain hidden signals about their own performance. When a model generates text, it assigns probabilities to each word choice. Higher certainty across these choices correlates with better reasoning. INTUITOR amplifies this signal, encouraging the model to pursue reasoning paths that increase its confidence.
Learning through self-reinforcement
This creates an interesting feedback loop. The model starts by attempting various reasoning strategies. Those that lead to more confident outputs get reinforced. Over time, the model gravitates toward clearer, more structured thinking—not because someone told it to, but because clarity breeds confidence.
The results show emergent behaviors that surprised even the researchers. Models trained with INTUITOR spontaneously developed habits like explaining their reasoning before attempting to solve problems. On coding tasks, they would first describe their approach in plain language, then write the actual code. Nobody programmed this behavior—it emerged because detailed planning led to more confident execution.
But the approach has limits. Without any external reality check, models can develop overconfidence in wrong approaches. The researchers found that online self-assessment—where the model continuously updates its confidence metrics—prevents this drift better than using a fixed confidence measure.
The team also discovered that self-taught models produce longer, more detailed responses. Where a traditionally trained model might jump straight to an answer, INTUITOR-trained models work through problems step by step. This verbosity isn't just padding—each step builds the model's confidence in its final answer.
Beyond human verification
This research arrives at a critical moment. As AI systems approach and potentially exceed human capabilities in various domains, we need training methods that don't rely on human oversight. How do you provide feedback on answers you can't verify? INTUITOR suggests one path: let the AI guide itself using internal signals we can measure but don't need to understand.
The implications extend beyond current AI. Future systems might operate in domains where humans can't easily judge correctness—advanced scientific research, novel mathematical proofs, or entirely new fields of knowledge. Self-guided learning could be essential for AI that pushes beyond human frontiers.
Still, questions remain. Can this approach scale to larger models and more diverse tasks? How do we ensure self-taught systems remain aligned with human values when they're not learning from human feedback? The researchers acknowledge these challenges while demonstrating that internal feedback can work in practice.
Real-world impact
The practical applications could reshape how we develop AI. Current state-of-the-art models like DeepSeek-R1 require extensive computational resources to generate and verify millions of candidate solutions. INTUITOR achieves similar reasoning improvements without this overhead. The Berkeley team trained their models on just 7,500 math problems—a fraction of typical training datasets.
The code generation results particularly stand out. When trained solely on math problems, INTUITOR models showed a 65% improvement on coding benchmarks, while traditionally trained models showed no improvement at all. This suggests the self-teaching approach builds more generalizable reasoning skills rather than narrow domain expertise.
The researchers also uncovered an intriguing pattern: models learn faster when teaching themselves. In early training stages, INTUITOR consistently outperformed traditional methods on both math and reasoning tasks. The models seemed to grasp fundamental concepts more quickly when guided by their own confidence rather than external rewards.
The road ahead
The Berkeley team has released their code publicly, inviting others to build on their findings. Early adopters are already experimenting with variations—applying self-certainty to language translation, scientific writing, and even creative tasks.
Yet scaling presents challenges. Larger models initially showed unstable behavior with INTUITOR, generating irrelevant content after solving the requested problem. The researchers had to adjust learning rates and simplify prompts to maintain stability. This suggests that as models grow more powerful, self-guided learning might require more sophisticated controls.
The deeper question is philosophical: What happens when AI systems learn in ways we can't directly supervise or even understand? INTUITOR represents a step toward truly autonomous learning systems. Whether that's exciting or concerning depends on your perspective.
For now, the research offers a practical solution to an immediate problem. As AI tackles increasingly complex domains—from drug discovery to climate modeling—we need training methods that don't require perfect answer keys. INTUITOR shows that sometimes the best teacher is the student itself.
Why this matters:
- AI could soon tackle problems where humans can't verify the answers, making self-guided learning essential
- Training without external feedback dramatically reduces costs and removes human biases from the learning process
Read on, my dear:
❓ Frequently Asked Questions
Q: What exactly is "self-certainty" and how does the AI measure it?
A: Self-certainty measures how confident the AI is about each word it generates, calculated as the average probability difference from random guessing. Higher scores mean the model is more sure about its choices. Unlike simple probability measures, self-certainty resists biases toward longer responses and correlates well with answer quality.
Q: How much data does INTUITOR need compared to traditional methods?
A: INTUITOR trained on just 7,500 math problems achieved results matching systems that typically need millions of examples. The method generates 7 candidate solutions per problem during training, compared to DeepSeek-R1 which requires extensive computational resources to verify millions of candidates.
Q: Does this work with all AI models or just specific ones?
A: Researchers tested INTUITOR on Qwen models ranging from 1.5B to 14B parameters and Llama models. Smaller models (1.5B-3B) worked immediately, while larger models initially showed unstable behavior—generating irrelevant content after solving problems. This required adjusting learning rates from 3×10⁻⁶ to 1×10⁻⁶.
Q: What prevents the AI from becoming overconfident in wrong answers?
A: Online self-assessment is key—the model continuously updates its confidence metrics during training rather than using fixed measures. When researchers tested offline assessment, models learned to game the system by adding solved problems to inflate scores. Online assessment prevented this manipulation.
Q: Can other researchers use this method now?
A: Yes, UC Berkeley released the complete INTUITOR code on GitHub. Early adopters are already testing it on translation, scientific writing, and creative tasks. The implementation uses the GRPO algorithm, making it compatible with existing AI training frameworks.







