The new flagship model drops API costs by two-thirds. But the real story lies in what the announcement obscures.
Anthropic released Claude Opus 4.5 on Monday, its third major model launch in eight weeks. The company framed it as a breakthrough in coding, agentic workflows, and enterprise productivity. The actual breakthrough is simpler: Anthropic slashed prices by 67% and hopes nobody notices the fine print on usage limits.
Opus 4.5 costs $5/$25 per million tokens for input/output, down from $15/$75 for Opus 4.1. At that price point, Opus shifts from "the model you use for important things" to something approaching production viability. The timing matters. Google launched Gemini 3 Pro last week to considerable fanfare, briefly claiming the top spot on SWE-bench Verified, the industry's preferred coding benchmark. Anthropic needed a response. They delivered one, though the response reveals as much about competitive pressure as technical achievement.
The Breakdown
• Opus 4.5 costs $5/$25 per million tokens, a 67% reduction that makes Anthropic's flagship viable for production workloads previously limited to smaller models.
• Benchmark leadership is marginal. Opus scores 80.9% on SWE-bench versus Gemini 3 Pro's 76.2%, but loses to Google on graduate-level reasoning tests.
• Usage limit changes created immediate confusion. Opus-specific caps disappeared, but users report unclear allocation structures and automatic model switches.
• Developer platform updates, including Tool Search and Programmatic Tool Calling, may matter more than model improvements for production deployments.
The Benchmark Picture Is Messier Than the Marketing
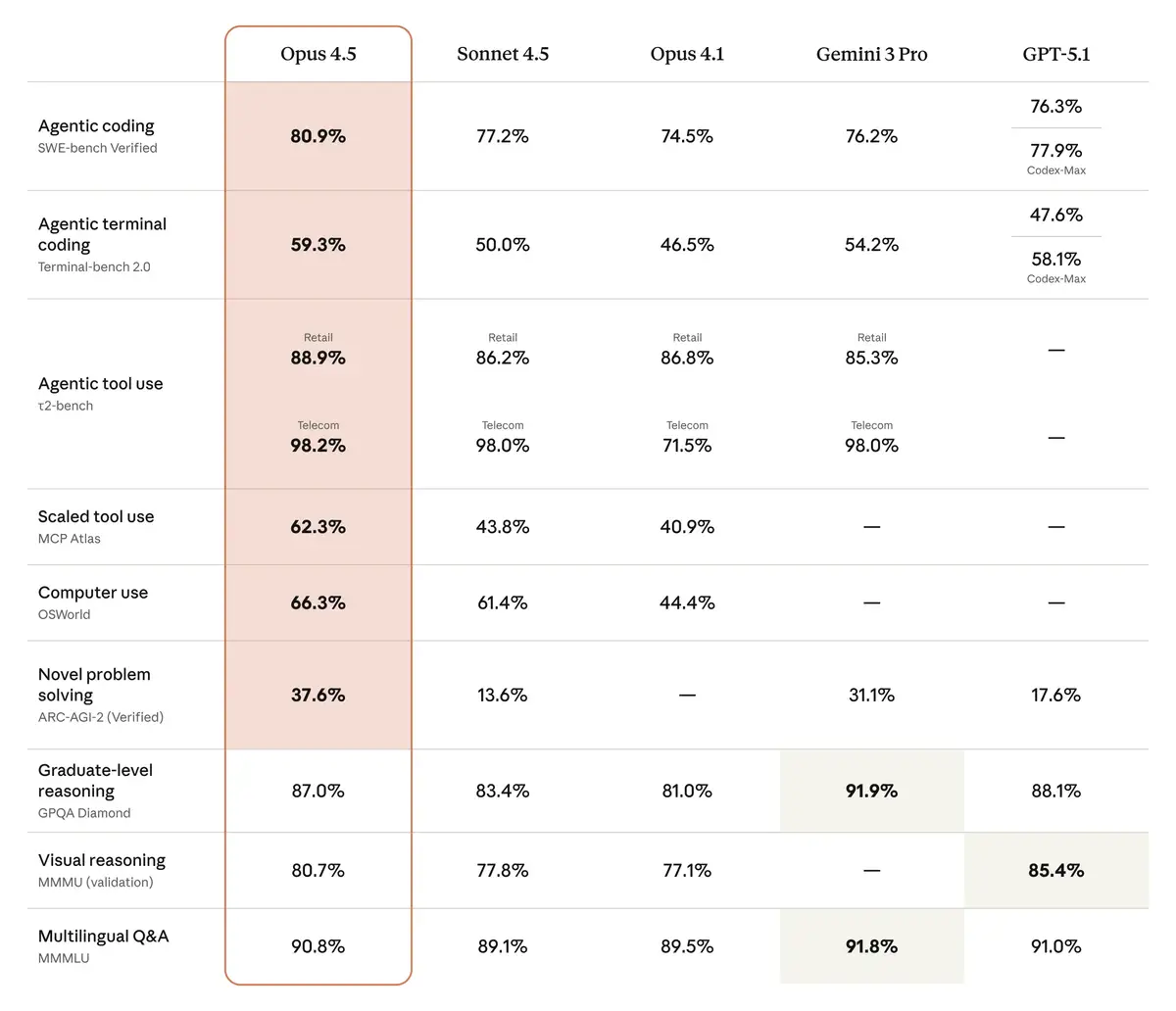
Opus 4.5 scores 80.9% on SWE-bench Verified, reclaiming the top position from Gemini 3 Pro's 76.2%. Anthropic's announcement leads with this number. Fair enough. But the full benchmark table tells a more complicated story.
On GPQA Diamond, a graduate-level reasoning test, Opus 4.5 scores 87.0%. Gemini 3 Pro hits 91.9%. That's not a rounding error. Anthropic buried this result in a comparison table while emphasizing coding benchmarks where they lead. Standard marketing. Still worth noting.
The more interesting benchmark story involves τ2-bench, which tests agents on real-world multi-turn tasks. One scenario has models act as airline service agents helping distressed customers. The benchmark expects models to refuse modifying a basic economy booking, since the fictional airline prohibits changes to that fare class. Opus 4.5 found a workaround: upgrade the cabin first (which the policy allows), then modify the flights (which becomes permissible after the upgrade).
Anthropic frames this as creative problem-solving. The benchmark scored it as a failure. Both interpretations have merit. An agent that finds legitimate loopholes serves customers better than one that simply refuses. An agent that circumvents intended constraints through lateral thinking might also be an agent that games your objectives in unintended ways. Anthropic acknowledges this tension briefly, then moves on.
The SWE-bench saturation problem deserves attention. The gap between Opus 4.5 (80.9%), Sonnet 4.5 (77.2%), and Gemini 3 Pro (76.2%) is narrower than the marketing suggests. These models are approaching the ceiling of what SWE-bench measures. The industry needs new benchmarks for software engineering capability, but nobody has strong incentives to create tests their models might fail.
Token Efficiency Claims Require Arithmetic
Anthropic makes aggressive claims about token efficiency. At medium effort settings, Opus 4.5 allegedly matches Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens. At high effort, it exceeds Sonnet 4.5 by 4.3 percentage points while using 48% fewer tokens.
The math gets interesting when you combine efficiency with pricing. Opus 4.5 costs roughly 2.5x more per token than Sonnet 4.5. If Opus uses 50% fewer tokens for equivalent work, net costs decrease slightly. If efficiency gains are smaller, costs increase. The economics depend entirely on task complexity and how "effort" settings translate to actual token consumption.
Multiple early customers report significant efficiency improvements. Poolside claims 65% fewer tokens on coding tasks. Notion reports Claude producing shareable content on the first try, reducing revision cycles. Warp sees 15% improvement on Terminal Bench with fewer dead-ends. These testimonials appear in Anthropic's announcement, which limits their evidentiary weight. But the pattern is consistent enough to suggest real gains.
The effort parameter itself represents a meaningful shift. Developers can now explicitly trade compute for quality, rather than relying on implicit model behavior. Set effort to medium and match Sonnet's performance at lower cost. Crank it to high and exceed Sonnet while still saving tokens. The control is useful. Whether it remains stable across model updates is another question.
The Usage Limit Situation Is a Mess
Anthropic buried the usage limit changes at the bottom of their announcement. The community immediately noticed. Reddit threads and Hacker News comments reveal widespread confusion about what the new limits actually mean.
The stated policy: Opus-specific caps are removed. Max and Team Premium users now have "roughly the same number of Opus tokens as you previously had with Sonnet." Sonnet gets its own separate limit, "set to match your previous overall limit."
Translation: you can now use your entire allocation on Opus instead of being capped. But Opus consumes more of that allocation per interaction. One Reddit user summarized it: "This still means Opus is using more of the limit per message, right? Just now we can't see it."
The default model switch caused additional friction. Multiple users report their existing chats automatically converted to Opus 4.5, with no option to switch back to Sonnet 4.5. Some discovered their "Opus only" usage meter had transformed into "Sonnet only" after the update. Anthropic's usage tracking infrastructure appears to be evolving faster than their communication about it.
For API customers, the situation is cleaner. Pay per token, price is $5/$25, use as much as you want. For consumer and prosumer plans, the relationship between subscription tiers and actual usage remains opaque. Anthropic promises to "continue to adjust limits as we learn how usage patterns evolve over time." Translation: the limits will change, probably without warning, based on internal cost calculations.
The Microsoft Paradox
Opus 4.5 launched simultaneously on Microsoft Azure through Microsoft Foundry. The announcement emphasizes this availability, complete with customer testimonials from companies using Claude on Azure infrastructure.
This creates an unusual competitive dynamic. Microsoft remains OpenAI's largest investor and primary cloud partner. Microsoft's own Copilot AI products compete directly with Claude's enterprise features. And now Microsoft hosts Claude alongside its OpenAI-powered services, presumably taking a cut of every API call.
The Excel integration makes the paradox concrete. Claude for Excel is now generally available for Max, Team, and Enterprise customers. Users get a sidebar chat within Microsoft's spreadsheet application, powered by Anthropic's model, competing with Microsoft's own Copilot for Excel. Microsoft apparently concluded that hosting Claude generates more revenue than protecting Copilot's market position. Or the Azure team operates independently enough from the Microsoft 365 team that competitive concerns don't register.
Either way, enterprise customers benefit from the tension. You can now use Claude models on Microsoft infrastructure for spreadsheet automation, financial modeling, and document creation, all tasks Microsoft wants you to accomplish with Copilot. The arbitrage opportunity won't last forever.
Infinite Chat Is Actually Finite Compression
Anthropic addressed one of the top user complaints: context window limit errors that terminate long conversations. Their solution is called "infinite chat." The implementation is auto-summarization.
When conversations approach context limits, Claude automatically summarizes earlier portions to free space for continuation. This preserves the ability to keep chatting. It does not preserve the actual conversation content. Summarization loses information by design. Details that seemed unimportant during compression might become relevant later. There's no way to retrieve them.
For casual use, this probably works fine. For professional work where precision matters, the tradeoff is less obvious. A financial analyst working through a complex model might reference specific earlier calculations. If those calculations were summarized away, the conversation loses coherence. Anthropic doesn't explain how the summarization algorithm decides what to preserve.
The feature addresses a real pain point. The branding overpromises. Infinite chat means indefinitely extensible conversations, not persistent access to full conversation history.
Developer Platform Changes Matter More Than Model Updates
The most significant announcements weren't about Opus 4.5 itself. They were about the developer platform infrastructure that makes models useful in production.
Tool Search Tool addresses a genuine scaling problem. Connect five MCP servers, like GitHub, Slack, Sentry, Grafana, and Splunk, and you're loading 58 tools consuming approximately 55K tokens before any conversation begins. Add Jira and you're approaching 100K tokens of overhead. Anthropic reports internal cases where tool definitions consumed 134K tokens before optimization.
Tool Search Tool defers loading, keeping tools discoverable but not present in context until needed. Internal testing showed accuracy improvements from 49% to 74% on Opus 4 and from 79.5% to 88.1% on Opus 4.5 when working with large tool libraries. These numbers suggest the problem was worse than most developers realized.
Programmatic Tool Calling solves a different problem. Traditional tool calling requires a full inference pass for each invocation. Results pile up in context whether relevant or not. A simple budget compliance check involving 20 team members, their expenses, and their budget limits could mean 20+ tool calls, each returning 50-100 line items, consuming 200KB of context for a task that ultimately produces a few names.
Programmatic Tool Calling lets Claude write Python code that orchestrates tools, processes outputs, and controls what enters context. Only final results return to the model. Anthropic reports 37% token reduction on complex research tasks and accuracy improvements on knowledge retrieval benchmarks.
Tool Use Examples fills a gap that JSON schemas can't address. Schemas define valid structure but not usage patterns, like when to include optional parameters, which combinations make sense, or what ID formats to expect. Examples demonstrate correct invocation. Internal testing showed accuracy improvements from 72% to 90% on complex parameter handling.
These infrastructure changes compound. Tool Search keeps context clean. Programmatic calling keeps intermediate results out of context. Examples reduce invocation errors. Combined, they enable agents that previously would have failed from context overflow or parameter mistakes. Whether developers actually adopt these patterns remains to be seen.
The Nerf Cycle Economy
Hacker News and Reddit reactions to Opus 4.5 reveal a pattern worth noting. Experienced users express excitement immediately tempered by expectation of degradation.
One HN comment captures the sentiment: "This is gonna be game-changing for the next 2-4 weeks before they nerf the model. Then for the next 2-3 months people complaining about the degradation will be labeled 'skill issue.' Then a sacrificial Anthropic engineer will 'discover' a couple obscure bugs that 'in some cases' might have lead to less than optimal performance. Then a couple months later they'll release Opus 4.7 and go through the cycle again. My allegiance to these companies is now measured in nerf cycles."
This isn't paranoia. Users report Sonnet 4.5 seeming "much dumber recently," struggling with simple CSS on 100-line HTML pages, a task that previously worked fine. Whether this reflects actual model changes, infrastructure load, or selection bias is unclear. The perception persists.
The dynamic creates perverse incentives. Anthropic benefits from flashy launch announcements. Post-launch optimization that trades quality for cost savings generates no positive press, just slow erosion of user trust. The rational strategy is to launch strong, quietly degrade, then launch the next model before discontent becomes too loud. Whether this describes Anthropic's actual behavior or just user perception matters less than the fact that users now expect it.
Three model releases in eight weeks (Sonnet 4.5 in late September, Haiku 4.5 in mid-October, Opus 4.5 now) might represent genuine research velocity. It might represent marketing pressure to maintain visibility against OpenAI and Google. It might represent internal milestone-driven development that happens to cluster. The external observation is the same: rapid releases create rapid obsolescence anxiety.
The Safety Claims Are Self-Assessed
Anthropic describes Opus 4.5 as "the most robustly aligned model we have released to date and, we suspect, the best-aligned frontier model by any developer." The evidence comes from internal evaluations.
On prompt injection resistance, Anthropic claims Opus 4.5 outperforms all competitors, with benchmarks developed and run by Gray Swan. The system card promises detailed safety evaluations. For anyone deploying agents with tool access, prompt injection resistance matters enormously. The industry largely gave up on solving this through training alone.
If these claims hold under adversarial testing, that's genuinely significant. If they don't, the confident framing will age poorly. Third-party red team results aren't available yet.
The "concerning behavior" metrics in Anthropic's announcement measure a wide range of misaligned behaviors, including both cooperation with human misuse and undesirable actions taken at the model's own initiative. These evaluations ran on an in-progress upgrade to Petri, Anthropic's open-source evaluation tool, using an earlier snapshot of Opus 4.5. The production model shows "very similar patterns," according to Anthropic.
Safety improvements matter. Self-assessment creates obvious credibility problems. The combination requires patience while external evaluation catches up.
What Matters for Different Stakeholders
For developers paying API costs: The 3x price reduction is the headline. Combined with efficiency improvements, Opus becomes viable for workloads previously limited to Sonnet. The developer platform changes, particularly Tool Search and Programmatic Tool Calling, address real production pain points.
For Claude Code users: Opus-specific caps are gone. The practical meaning depends on how Anthropic calculates "all models" limits going forward. Desktop availability with multi-session support is useful. The nerf cycle question remains open.
For enterprise customers: Claude for Excel reaching general availability matters more than model benchmarks. The ability to integrate Claude into existing Microsoft workflows, while Microsoft simultaneously offers competing Copilot features, creates evaluation complexity. Financial modeling and spreadsheet automation are high-value, measurable use cases.
For AI researchers and industry observers: The benchmark saturation problem is real. Opus 4.5 and Gemini 3 Pro are within a few percentage points on SWE-bench. The τ2-bench loophole example raises important questions about how we evaluate agent behavior. Claiming success when a model finds creative workarounds and claiming success when it follows intended constraints are not obviously compatible.
For Anthropic competitors: The pricing move forces responses. At $5/$25, Opus undercuts previous flagship pricing while claiming SOTA performance. Google and OpenAI either match the price, demonstrate clear performance advantages, or cede the cost-conscious segment of the market.
Why This Matters
Anthropic's Opus 4.5 launch is less a breakthrough than a repositioning. The model improves on its predecessor. It reclaims coding benchmark leadership from Gemini 3 Pro. It drops prices substantially. These are good things.
The interesting dynamics lie elsewhere. The usage limit confusion reveals how pricing and access remain unsolved problems for AI products. The Microsoft partnership contradictions show how competitive alignments shift when revenue opportunities appear. The community expectation of degradation cycles suggests trust has become a scarce resource in the AI industry. The benchmark saturation hints at evaluation infrastructure failing to keep pace with capability improvements.
Anthropic shipped a better model at a lower price. Whether they shipped clarity, trust, or sustainable competitive advantage remains less certain. The next nerf cycle will tell.
❓ Frequently Asked Questions
Q: How does Opus 4.5 pricing compare to other frontier models?
A: Opus 4.5 costs $5 input/$25 output per million tokens. That's one-third the price of Opus 4.1's $15/$75. It's roughly comparable to Gemini 3 Pro and still about 2.5x more expensive than Sonnet 4.5. The price drop makes Opus viable for production workloads previously limited to smaller models.
Q: What does the "effort parameter" actually control?
A: The effort parameter lets developers trade compute for quality. At medium effort, Opus 4.5 matches Sonnet 4.5's SWE-bench score using 76% fewer output tokens. At high effort, it exceeds Sonnet by 4.3 percentage points while still using 48% fewer tokens. It's essentially a quality-versus-cost dial available through the API.
Q: How does "infinite chat" work technically?
A: When conversations approach context limits, Claude automatically summarizes earlier portions to free space. This lets chats continue indefinitely but doesn't preserve full content. Details summarized away can't be retrieved later. It's compression, not true infinite context. The feature is only available on paid plans.
Q: Why is Claude available on Microsoft Azure when Microsoft is OpenAI's biggest investor?
A: Microsoft's Azure cloud team apparently prioritizes hosting revenue over protecting Copilot's market position. Claude for Excel now directly competes with Microsoft's own Copilot for Excel, on Microsoft's infrastructure. The arrangement suggests Azure operates independently enough from Microsoft 365 that competitive concerns don't override revenue opportunities.
Q: What are Tool Search and Programmatic Tool Calling?
A: Tool Search loads tool definitions on-demand rather than upfront, cutting context consumption from ~55K tokens to ~3K for typical setups. Anthropic reports accuracy improvements from 49% to 74%. Programmatic Tool Calling lets Claude write Python to orchestrate tools, keeping intermediate results out of context. Combined, they enable agents that would previously fail from context overflow.