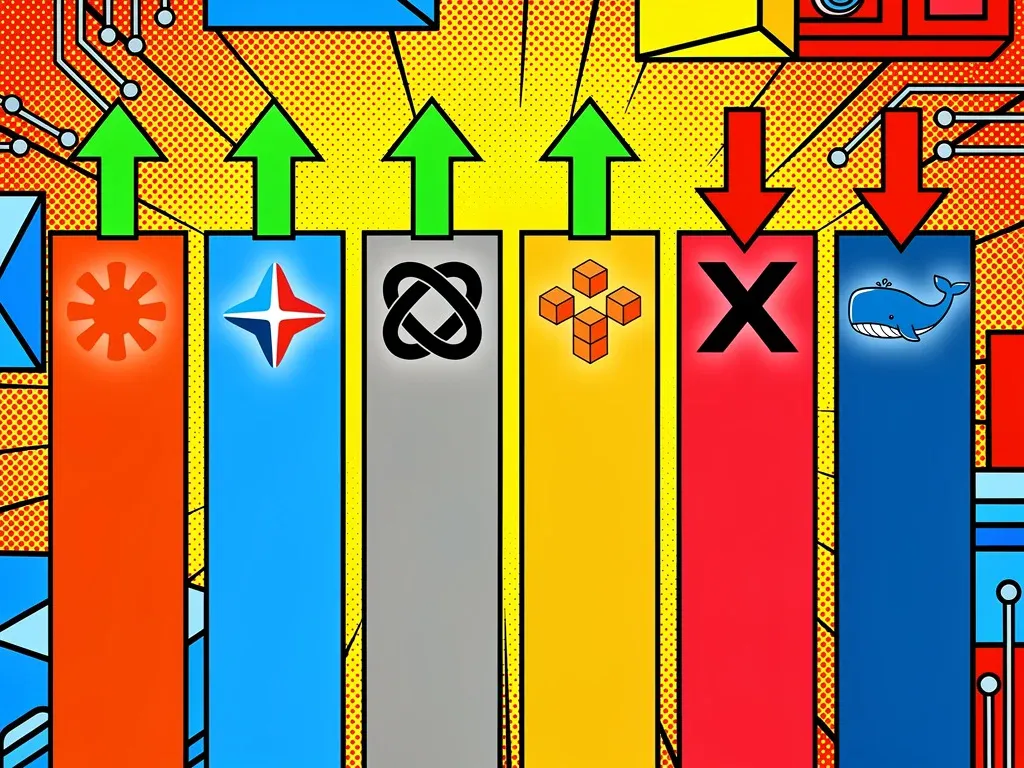
OpenAI's ChatGPT rose two points to 86 on Implicator's weekly LLM Meter for the week of June 8, narrowing Google Gemini's lead to a single point, while Anthropic's Claude slipped one point to 90 and kept the top spot. The scorecard rates six large language models from an enterprise-buyer perspective and tracks week-over-week movement. No model changed rank.
Key Takeaways
- ChatGPT rose two points to 86 on Implicator's June 8 LLM Meter, cutting Gemini's lead to one point.
- The gain followed OpenAI's GPT-5.5, GPT-5.4, and Codex reaching general availability on Amazon Bedrock June 1.
- Claude slipped to 90 but held first place after two June outages, even as Anthropic filed for an IPO.
- Mistral, Grok, and DeepSeek held their ranks; DeepSeek rose on a reported $7.4 billion raise.
AI-generated summary, reviewed by an editor. More on our AI guidelines.
ChatGPT closes on Gemini
ChatGPT's two-point gain followed OpenAI's arrival on Amazon Web Services. GPT-5.5, GPT-5.4, and the Codex coding agent became generally available on Amazon Bedrock on June 1, according to AWS, with pricing matched to OpenAI's first-party rates and usage counting toward customers' existing AWS commitments. The change lets enterprises run OpenAI models through AWS governance controls such as IAM permissions, encryption, and CloudTrail logging, adding to Microsoft Azure and OpenAI's own API. Amgen and Autodesk said they were evaluating the models on Bedrock.
Track the enterprise AI race
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
The gap to Gemini, four points a week earlier, closed to one as Gemini slipped a point to 87. Google's Gemini 3.5 Pro, announced at the company's I/O conference on May 19, remained in limited preview as of June 6 rather than reaching general availability, TechTimes reported, a second consecutive week without the flagship shipping. Gemini's enterprise platform and customer roster were unchanged.
Claude slips after two outages
Claude's one-point decline came in a week that also brought corporate milestones. Anthropic confidentially submitted a draft Form S-1 to the Securities and Exchange Commission on June 1, the company said, giving it the option of an initial public offering after the SEC completes its review. The filing followed a $65 billion Series H last month that valued Anthropic at $965 billion.
Know someone who'd find this useful? ✉️ Email it to a friend in one click, or they can subscribe free here.
Two service disruptions offset those gains. Claude returned capacity-constraint errors in an outage on June 2 that affected its web app, developer console, and Claude Code, The National reported, with a second reported disruption on June 5. Reports linked the June 2 failure to a bug in Claude Code's sub-agent system that drained some Pro and Max user quotas; Anthropic issued automated resets. Claude kept the meter's top marks for coding quality and compliance.
Mistral, Grok, and DeepSeek
Mistral slipped a point to 72 on a week with no fresh enterprise catalyst. Its strongest asset, the open-weight Mistral Large 3, shipped in December 2025 and was not new this week. Grok rose a point to 31; the meter credited new xAI consumer and developer features, including Grok Voice, while noting no enterprise compliance or procurement progress. DeepSeek rose to 18 after Reuters reported it is raising about $7.4 billion at a valuation of up to $59 billion, with Tencent and battery maker CATL reportedly in talks to participate. The meter continued to flag U.S. procurement and compliance risk.
The next weekly update is due June 15.
Frequently Asked Questions
What is the Implicator LLM Meter?
It is a weekly editorial scorecard from Implicator that rates six large language models, Claude, Gemini, ChatGPT, Mistral, Grok, and DeepSeek, from the perspective of business and enterprise buyers. Each model gets a score from 0 to 100 and an up or down trend based on the week's developments in compliance, model quality, reliability, ecosystem maturity, vendor stability, and pricing.
Why did ChatGPT rise this week?
OpenAI's GPT-5.5, GPT-5.4, and Codex coding agent reached general availability on Amazon Bedrock on June 1, letting enterprises run OpenAI models through AWS governance and billing. The meter scored that distribution expansion as ChatGPT's strongest enterprise move of the week, lifting it two points to 86 and cutting Gemini's lead to one point.
Why did Claude slip if Anthropic filed for an IPO?
The confidential S-1 filing was a positive vendor-stability signal, but two Claude service outages, on June 2 and June 5, weighed against it. The June 2 disruption returned capacity-constraint errors and, per reports, drained some Pro and Max quotas before resets. Claude still kept the meter's top score, at 90.
Where does Gemini stand?
Gemini slipped one point to 87 and remains second. Google's flagship Gemini 3.5 Pro, announced at I/O on May 19, was still in limited preview as of June 6 rather than generally available, a second straight week without the model shipping. Its enterprise platform and customer roster were unchanged.
How did Mistral, Grok, and DeepSeek do?
Mistral slipped to 72 on a quiet week; its Mistral Large 3 model launched in December 2025, not this week. Grok rose to 31 on new consumer and developer features. DeepSeek rose to 18 after Reuters reported a roughly $7.4 billion funding round that could value it up to $59 billion.
AI-generated summary, reviewed by an editor. More on our AI guidelines.



Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai