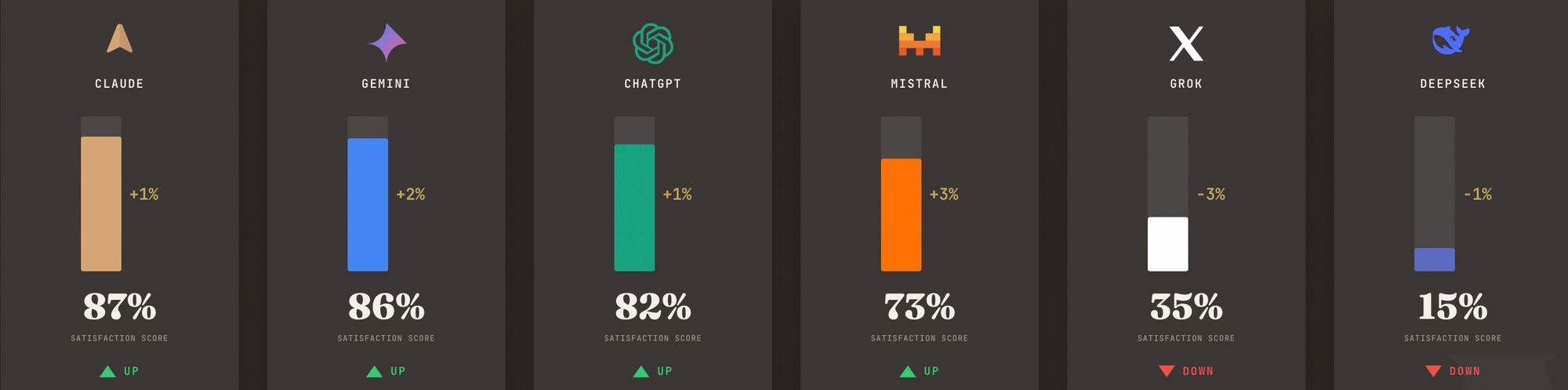
The Implicator's LLM Meter for May 3 ranked Anthropic's Claude first at 87, one point above Google's Gemini at 86 after Google secured a classified Pentagon contract that Anthropic had declined. Mistral posted the week's largest move, rising three points to 73 after launching its Workflows orchestration platform on April 28 with European enterprise customers including ASML and La Banque Postale. xAI's Grok fell three points to 35 after a multi-day platform outage and Elon Musk's testimony that xAI had used distillation of OpenAI models to train Grok.
Key Takeaways
- Anthropic's Claude held the LLM Meter lead at 87 after launching Claude Security to all Enterprise customers on May 1.
- Google's Gemini rose two points to 86 after taking the Pentagon classified contract Anthropic declined in March.
- Mistral posted the largest weekly move, up three points to 73 after launching its Workflows orchestration product on April 28.
- Grok fell three points to 35 after a multi-day outage and Musk's testimony on OpenAI model distillation.
AI-generated summary, reviewed by an editor. More on our AI guidelines.
Anthropic stays first on Security launch and NSA work
Anthropic moved Claude Security from a February research preview to public beta on May 1, releasing the codebase scanner to all Claude Enterprise customers. The product runs on Opus 4.7 and ships with partner integrations from CrowdStrike, Microsoft Security, Palo Alto Networks, SentinelOne and Wiz. Bloomberg reported on April 30 that the National Security Agency has been testing Anthropic's Claude Mythos Preview against Microsoft software. The White House continues to oppose Anthropic's plan to expand Mythos access to about 120 organizations, and the Pentagon's supply-chain risk designation remains in court.
Google takes the Pentagon slot Anthropic refused
The Pentagon's classified deal with Google was confirmed on April 28 by U.S. Defense Department officials, who said Gemini would be available for "any lawful governmental purpose." Google takes the seat vacated by Anthropic, which the Department of Defense designated a supply-chain risk in March after Anthropic refused to remove usage-policy carve-outs prohibiting domestic surveillance and lethal autonomous weapons. More than 600 Google employees, many from DeepMind, signed an open letter to Sundar Pichai opposing the classified work. Macquarie Bank disclosed 130,000 hours saved across seven months of Gemini Enterprise usage, and Google moved Gemini 3.1 Flash-Lite to general availability.
Mistral posts the largest weekly move
Mistral's Workflows release is built on Temporal's durable execution engine, the same orchestration layer used by Netflix and Stripe. Mistral said launch customers ASML, ABANCA, CMA-CGM, France Travail, La Banque Postale and Moeve are running millions of executions a day. The architecture splits a Mistral-managed control plane from a customer-side data plane, addressing European data-residency and sovereign-AI procurement review. Mistral also released Mistral Medium 3.5, a 128-billion-parameter dense open-weight model, on Hugging Face during the same window.
Stay ahead on enterprise AI procurement
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
Grok and DeepSeek lose ground
Grok's multi-day outage began April 21, with users in the United States, Europe and Asia reporting "high demand" errors for more than 48 hours while xAI's status page reported the service as fully operational. On April 30, Musk testified in Musk v. Altman that xAI had "partly" used distillation of OpenAI models to train Grok, calling it "standard practice to use other AIs to validate your AI." DeepSeek dropped one point to 15 after the National Institute of Standards and Technology's Center for AI Standards and Innovation released a May 2026 evaluation finding that DeepSeek V4 Pro lags the frontier by approximately eight months and performs similarly to GPT-5 from August 2025.
ChatGPT moves up on AWS distribution
ChatGPT rose one point to 82 after OpenAI launched its models on Amazon Bedrock on April 28, one day after Microsoft and OpenAI dropped Azure exclusivity. The Wall Street Journal reported on April 28 that OpenAI missed its end-of-2025 weekly active user target of one billion and faces about $600 billion in future compute commitments ahead of a possible public listing. Altman and Brockman are expected to testify in the Musk v. Altman trial in Oakland later this month.
Frequently Asked Questions
What is The Implicator's LLM Meter?
A weekly enterprise-buyer scorecard for the major large language model families. It tracks Claude, ChatGPT, Gemini, Mistral, Grok and DeepSeek using product launches, reliability, pricing, distribution and compliance signals from the past nine days. The May 3 edition placed Claude first at 87, Gemini second at 86, ChatGPT third at 82, Mistral fourth at 73, Grok fifth at 35 and DeepSeek sixth at 15.
Why did Mistral post the largest gain this week?
Mistral rose three points to 73 after launching its Workflows orchestration product on April 28. The Temporal-based system runs millions of executions a day at ASML, ABANCA, CMA-CGM, France Travail, La Banque Postale and Moeve. Mistral also released Mistral Medium 3.5, a 128-billion-parameter dense open-weight model, on Hugging Face the same window.
What is Claude Security?
An Anthropic vulnerability scanner for source code, released to all Claude Enterprise customers on May 1 as a public beta. It runs on Opus 4.7 and ships with partner integrations from CrowdStrike, Microsoft Security, Palo Alto Networks, SentinelOne and Wiz. The product validates findings, recommends patches and supports scheduled scans for continuous coverage.
Why did Grok fall three points?
A multi-day outage that began April 21 left users in the United States, Europe and Asia hitting 'high demand' errors for more than 48 hours. On April 30, Elon Musk testified in Musk v. Altman that xAI had 'partly' used distillation of OpenAI models to train Grok. Both items affect enterprise procurement around vendor reliability and training-data attestation.
What did the CAISI evaluation find about DeepSeek V4?
The National Institute of Standards and Technology's Center for AI Standards and Innovation released a May 2026 evaluation finding that DeepSeek V4 Pro lags the frontier by approximately eight months, with capabilities similar to GPT-5 from August 2025. CAISI also reported V4 was more cost-efficient than the GPT-5.4 mini reference on five of seven benchmarks.
AI-generated summary, reviewed by an editor. More on our AI guidelines.



Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: [email protected]


