


Moonshot AI dropped Kimi K2.5 on a Tuesday. Not a coincidence. Everyone in Beijing knows DeepSeek has something big coming, and nobody wants to be second in line when the cameras turn.
The release carries a whiff of urgency. Moonshot built something genuinely novel, a model that can direct a hundred AI agents simultaneously, chewing through tasks that would otherwise require sequential execution. One trillion parameters, 32 billion active at any moment. But the company seems anxious to establish the achievement before DeepSeek steals the narrative. The Alibaba-backed startup isn't just matching American frontier labs. It's running a different race while looking over its shoulder at a domestic rival.
The swarm that coordinates itself
Kimi K2.5 introduces something the industry hasn't seen at this scale: an agent swarm that spawns and orchestrates its own sub-agents without human-designed workflows. Ask it to identify top YouTube creators across a hundred niche domains, and the model creates a hundred parallel searchers, each operating independently before aggregating results into a spreadsheet.
The Breakdown
• Moonshot's Kimi K2.5 can orchestrate 100 AI agents in parallel, cutting task runtime by 80%
• DeepSeek-OCR 2 introduces 'visual causal flow' to mimic human reading patterns, hitting 91% accuracy
• Chinese labs are racing to release before DeepSeek's anticipated announcement
• Kimi K2.5 matches GPT-5.2 and Claude 4.5 Opus on agentic benchmarks at lower cost
The technical mechanics matter here. Moonshot trained an orchestrator using what they call Parallel-Agent Reinforcement Learning. The system faced a common failure mode during development: serial collapse, where the model defaulted to doing everything sequentially despite having parallel capacity. Their solution involved staged reward shaping that incentivized parallelism early in training, then gradually shifted focus toward task completion.
The math behind it defines "Critical Steps" as the sum of orchestration overhead plus the slowest sub-agent at each stage. Spawning more agents only helps if it shortens this critical path. In their internal testing, the swarm reduced end-to-end runtime by 80 percent while handling more complex workloads.
This approach carries trade-offs. Running a hundred concurrent agents burns compute faster than sequential processing. The economics work for cloud deployment through Moonshot's API, but the 1 trillion parameter model requires serious hardware for local inference. A single 8xH100 server fits it with overhead room for the key-value cache. Your laptop does not.
The race for the release window
If you've watched Chinese AI funding over the past year, the velocity here stands out. Bloomberg reported that Moonshot raised $500 million last month at a $4.3 billion valuation, with investors now circling for another round at $5 billion. The funding surge follows IPOs by rivals Zhipu and MiniMax in Hong Kong, collectively raising over a billion dollars.
The timing feels deliberate, and the anxiety is palpable. Alibaba launched a reasoning version of Qwen3-Max the day before Kimi K2.5 dropped. Ant Group announced a robotics model the day after. Zhipu released an image generation model trained entirely on Huawei chips two weeks prior. Everyone positioning before DeepSeek makes its move, nervous about being overshadowed by whatever Liang Wenfeng's lab has planned.
And DeepSeek keeps dropping hints. The lab published a technical paper this week on DeepSeek-OCR 2, revealing a different architectural bet on how AI should process visual information.
Teaching machines to read like humans
Join 10,000+ AI professionals
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
Standard vision models scan images mechanically: top-left to bottom-right, pixel by pixel, row by row. DeepSeek's researchers argue this contradicts how humans actually see. Your eyes don't traverse a document in raster order. They jump to what matters, following semantic meaning rather than spatial coordinates.
DeepSeek-OCR 2 attempts to replicate this behavior through what they call "visual causal flow." Picture a bank statement with columns of transactions, headers, footnotes, and a logo in the corner. A raster scan reads the logo before the account balance. Human eyes skip straight to the numbers that matter. The encoder learns to reorder visual tokens based on content, not where things appear spatially.
The architecture replaces the standard CLIP vision encoder with a language model using bidirectional attention for visual tokens and causal attention for learnable query tokens. These queries attend to all visual information plus preceding queries, progressively reordering what the model "sees." A spiral diagram, a multi-column magazine spread, a dense academic paper with equations in the margins: the model learns reading patterns specific to each layout.
Results on OmniDocBench, a benchmark with 1,355 document pages across nine categories, show 91.09 percent accuracy while using fewer visual tokens than competitors. Reading order improved, dropping edit distance from 0.085 to 0.057 compared to the previous version. The model handles complex layouts, formulas, and tables that trip up conventional approaches.
Different bets on the same problem
You can think of these releases as two construction crews attacking the same building from different entry points. Moonshot entered through the front door: take existing model architectures and teach them to coordinate at scale. DeepSeek went through the foundation, rethinking how visual information gets into the model in the first place. Both crews want the same thing. They disagree about what's blocking progress.
Moonshot bets on coordination, letting a single powerful model spawn specialized workers. DeepSeek bets on perception, rebuilding how machines ingest visual information at the architectural level. Both approaches address real bottlenecks. Sequential agent execution wastes time when tasks can parallelize. Raster-order visual processing ignores the semantic structure of documents. The question is which constraint matters more for the applications companies actually need.
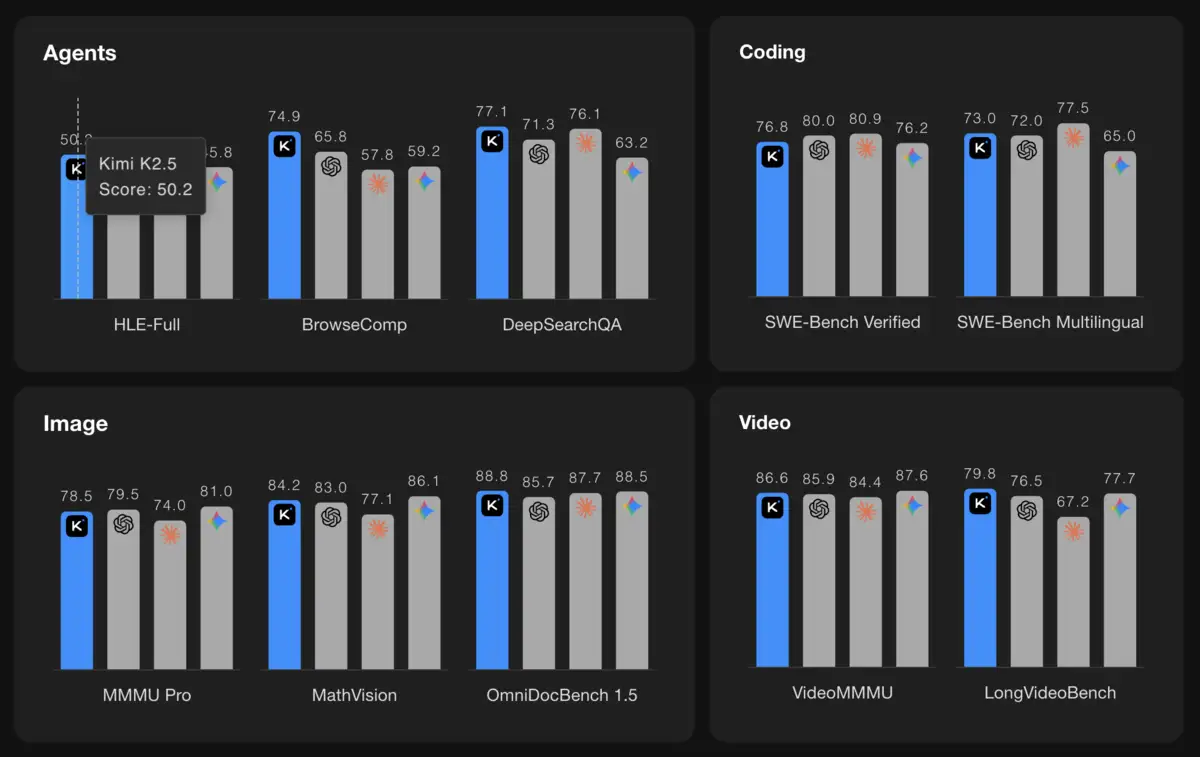
Moonshot positions Kimi K2.5 for knowledge work: coding, document processing, research synthesis. The benchmarks show competitive results against GPT-5.2 and Claude 4.5 Opus across coding and agentic search tasks, often at lower cost. Their HLE score with tools reached 50.2 percent, compared to 45.5 percent for GPT-5.2 and 43.2 percent for Claude 4.5 Opus. On SWE-Bench Verified, the coding evaluation, K2.5 hit 76.8 percent.
DeepSeek-OCR 2 targets a narrower problem but one that underpins broader ambitions. Accurate document parsing feeds training data pipelines. Better visual understanding enables multimodal reasoning. The paper hints at future directions: unified encoders that handle text, images, and audio through the same architecture with modality-specific query embeddings.
The open source calculus
Moonshot released K2.5 under MIT license with a wrinkle: products with over 100 million monthly users or $20 million in monthly revenue must display "Kimi K2.5" prominently in their interface. Not a fee. Branding rights.
The decision trades potential licensing revenue for market presence. A company making $240 million annually from a K2.5-powered product pays nothing but must acknowledge Moonshot in their UI. The bet seems to be that visibility matters more than money at this stage of the competition.
Daily at 6am PST
Don't miss tomorrow's analysis
No breathless headlines. No "everything is changing" filler. Just who moved, what broke, and why it matters.
Free. No spam. Unsubscribe anytime.
DeepSeek released OCR 2 with code and weights on GitHub. The 3 billion parameter model runs on consumer hardware, unlike Kimi's trillion-parameter behemoth. Different target audiences, different open source strategies.
What happens next
DeepSeek hasn't announced what it's building. The lab's co-founder Liang Wenfeng appeared on papers released this month. GitHub commits hint at infrastructure work. The AI community watches for signals the way traders watch Fed minutes.
Moonshot founder Yang Zhilin, formerly of Tsinghua University and Google, trails competitors in commercialization despite technical achievements. The K2.5 release pushes hard on enterprise productivity use cases. The swarm architecture suggests ambition beyond chatbots.
The broader pattern matters for anyone watching the AI industry. A year ago, frontier capability lived exclusively in San Francisco labs. Chinese companies now compete directly on benchmarks while exploring architectural directions American labs haven't prioritized. The gap between closed frontier models and open alternatives keeps shrinking.
OpenAI and Anthropic haven't said much publicly about this shift. The silence reads as guarded, neither dismissive nor panicked. Their models still top most benchmarks. Their enterprise customers aren't leaving. But the comfortable lead that justified premium pricing and measured release schedules looks less comfortable every month. When an Alibaba-backed startup matches your flagship model on agentic tasks at a fraction of the cost, the strategic calculus changes.
One trillion parameters, deployed globally, trained on techniques developed in Hangzhou and Beijing. The American companies still lead. The lead keeps getting smaller.
Frequently Asked Questions
Q: How many parameters does Kimi K2.5 have?
A: Kimi K2.5 has 1 trillion total parameters with 32 billion active at any moment. The mixture-of-experts architecture means only a fraction of the model runs for each task. Running it locally requires an 8xH100 server setup.
Q: What is 'serial collapse' in agent training?
A: Serial collapse occurs when a model trained for parallel execution defaults to running tasks sequentially. Moonshot addressed this by using staged reward shaping that incentivizes parallelism early in training, then gradually shifts focus toward task completion quality.
Q: How does DeepSeek-OCR 2 differ from standard vision models?
A: Standard models scan images in raster order, top-left to bottom-right. DeepSeek-OCR 2 uses 'visual causal flow' to reorder visual tokens based on semantic meaning, mimicking how humans actually read documents by jumping to what matters first.
Q: What are the licensing terms for Kimi K2.5?
A: Moonshot released K2.5 under MIT license with one condition: products with over 100 million monthly users or $20 million monthly revenue must prominently display 'Kimi K2.5' in their interface. No licensing fees, just branding requirements.
Q: Why are Chinese AI labs releasing models so quickly right now?
A: DeepSeek has signaled a major release is coming. Rivals including Moonshot, Alibaba, and Zhipu are rushing to establish their achievements before DeepSeek potentially dominates the news cycle. The lab's co-founder appeared on papers this month, fueling speculation.









