
💡 TL;DR - The 30 Seconds Version
👉 Factory raises $50M Series B from NEA, Sequoia, Nvidia, and J.P. Morgan while launching Droids AI coding agents that hit #1 on Terminal Bench.
📊 Enterprise customers report 31x faster feature delivery and 96.1% shorter migration times using Factory's multi-LLM platform approach.
🏭 The platform works across IDEs, terminals, Slack, and browsers, integrating with GitHub, Jira, and other enterprise tools developers already use.
🌍 Strategic investors signal different market perspectives: Nvidia sees compute demand, J.P. Morgan validates enterprise adoption acceleration.
🚀 Factory bets "agnostic" platforms beat integrated solutions as AI coding capabilities commoditize across major tech companies.
⚖️ The startup faces platform challenges against incumbents like GitHub Copilot with deeper distribution advantages and existing developer relationships.
Droids top a key terminal benchmark as Factory pushes an agnostic, enterprise-first platform
Factory made a double splash on Wednesday: a $50 million Series B and the general release of Droids, its software-development agents, which now sit atop the [Terminal-Bench public leaderboard] for real terminal tasks. The company argues its edge isn’t a single model or IDE—it’s meeting developers where they already work.
What’s actually new
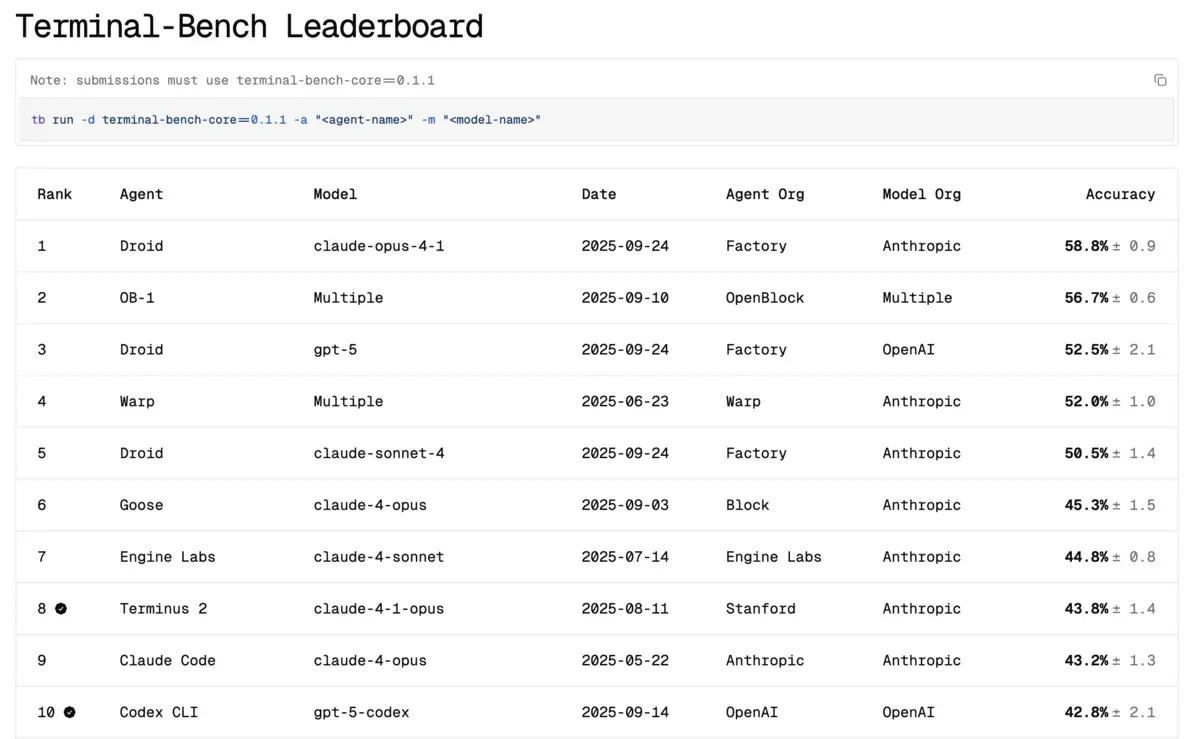
On September 24, 2025, Factory’s entries—Droid (Claude Opus 4-1) and Droid (GPT-5)—ranked #1 and #3 on Terminal-Bench, with 58.8% and 52.5% task-success respectively. That matters because Terminal-Bench tests end-to-end, multi-step workflows in a live shell, closer to how ops and build systems behave than synthetic code puzzles. It’s not everything, but it’s nearer to reality than autocomplete demos.
The product posture is deliberately “agnostic.” Factory exposes Droids across the IDE, CLI, browser, Slack/Teams, and project tools, rather than prescribing one stack. Developers can delegate from familiar surfaces and scale that delegation into CI/CD and long-running jobs without switching editors or vendors. It’s a distribution strategy as much as a UX choice.
Evidence beyond the demo reel
Factory’s docs and case studies sketch an enterprise integration map—GitHub/GitLab for source, Jira/Linear for planning, Slack/Teams for orchestration, and Sentry/PagerDuty for incidents—so agents can pull real context and push real changes. That’s the connective tissue required for “agent-native” claims. Early case studies (e.g., Clari and Empower) emphasize faster incident response, shorter cycles, and agent-assisted code review—concrete but bounded outcomes compared with sweeping “10x developer” promises.
Factory has also been laying enterprise plumbing: a May GA release positioned Droids to work across the SDLC, and a July listing on Microsoft’s Azure Marketplace lowers procurement friction for customers with MACC budgets. These are small but telling distribution wins for a startup selling workflow change, not just a shiny IDE add-in.
The money and the message
Factory says it raised $50 million from NEA, Sequoia, NVIDIA, and J.P. Morgan, with angels including Frank Slootman, Nikesh Arora, and Aaron Levie. The mix hints at a thesis that spans compute demand (NVIDIA), enterprise adoption (J.P. Morgan as beachhead buyer/integrator), and classic platform ambition (NEA/Sequoia). The company’s own site has long listed those firms and operators as backers; the fresh capital is aimed at expanding product, enterprise rollouts, and hiring across research and go-to-market.
The strategic calculation is clear: if coding assistance keeps commoditizing at the model layer, the defendable moat shifts to orchestration, context, and policy—the layer where agents coordinate real changes across repos, tickets, and incident systems, while preserving developer control and audit trails. That’s where budgets live.
Competitive context
The risk is that distribution beats design. GitHub Copilot, Google, and Microsoft bundle agentic features ever deeper into tools and clouds most teams already pay for. Factory’s counter is to be multi-LLM and multi-interface from day one, claiming better fit for heterogeneous environments and regulated buyers who need to mix models and execution tiers. Benchmarks like Terminal-Bench help establish credibility with practitioners, but incumbents can and do submit to the same tests.
A more durable path is proving that cross-tool agents drive measurable, line-of-business outcomes—fewer pages, shorter migrations, faster time-to-value on big refactors—and doing so with governance that satisfies the CISO and the VP of Eng. That’s why the integrations and marketplace listings matter: they shrink the “yes” path.
Caveats and what to watch
Benchmarks are not production. Terminal-Bench measures terminal competence under controlled runs; real shops wrestle with flaky envs, mixed stacks, flaky tests, and human handoffs. Case-study gains are directionally useful but not a universal law, and percentage improvements can mask absolute baselines. The next six months should tell us whether “agent-native” becomes a stable pattern—complete with runbooks, lint-as-policy, and change-management norms—or remains a power-user overlay on today’s SDLC.
Why this matters
- Agent platforms are shifting value from model choice to orchestration, policy, and enterprise integration—the part budgets actually map to.
- If startups like Factory can prove durable, auditable gains across incidents, migrations, and refactors, they force incumbents to compete on workflow depth, not just model quality.
❓ Frequently Asked Questions
Q: What is Terminal Bench and why does ranking #1 matter?
A: Terminal Bench tests AI agents on real command-line tasks in live shell environments, measuring end-to-end workflow completion rather than code generation alone. Factory's Droids achieved 58.8% task success versus competitors like Claude Code and Cursor. It's closer to production reality than synthetic coding puzzles.
Q: How much does Factory cost compared to GitHub Copilot?
A: Factory offers three tiers: free BYOK (bring your own API keys), Pro at $20/month with dedicated compute and frontier models, and custom Enterprise pricing. GitHub Copilot costs $10/month individual, $19/month business. Factory's Pro tier targets the same market with additional model flexibility.
Q: What does "agent-native development" actually mean for day-to-day coding?
A: Instead of autocompleting lines of code, developers delegate entire tasks like "migrate this API to v3" or "fix the production incident." Agents handle implementation details while developers focus on architecture and design decisions. It's orchestration rather than assistance.
Q: How does Factory's enterprise integration actually work in practice?
A: Factory connects to existing tools like GitHub for code, Jira for tickets, Slack for notifications, and Datadog for monitoring. When agents make changes, they create pull requests, update tickets, and send status updates through normal channels. The goal is preserving existing workflows while adding automation.
Q: Can Factory really compete with Microsoft's GitHub Copilot built-in advantages?
A: Factory's defense is flexibility—working across multiple LLMs, IDEs, and cloud providers versus single-vendor lock-in. Enterprise customers often use mixed environments that favor vendor-agnostic solutions. However, Microsoft's 100+ million GitHub users and native VS Code integration create formidable distribution advantages.

Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


