
Last Tuesday, Google pushed an update to Gemini 3 Deep Think. Today, one week later, those same reasoning capabilities went live in Gemini 3.1 Pro, the production flagship available to every developer and paying consumer on the platform.
On ARC-AGI-2, a test designed to measure whether AI models can solve logic patterns they've never seen before, Gemini 3.1 Pro scored 77.1%. In November, Gemini 3 Pro scored 31.1% on the same test. That's a 2.5x improvement in three months. No lab has shipped a reasoning jump this steep in this short a window. On GPQA Diamond, the PhD-level science benchmark, 3.1 Pro hit 94.3%, a new all-time high, topping GPT-5.2's 92.4%.
Google's blog post calls this "a step forward in core reasoning." That is the most boring possible description of what happened.
The number is the easy part of this story. The harder question, and the one that should have engineers across three time zones refreshing benchmark tables at 2 a.m., is what it reveals about the improvement machine running behind that number. Google didn't just build a better model. It showed it can move a breakthrough from its research lab into production for millions of users in seven days flat. Google didn't hold a product launch. It opened an assembly line.
The three labs that dominate this race have each staked out different ground. OpenAI owns consumer habits. Anthropic leads on code generation and developer tooling. Google, as of today, holds the top score on abstract reasoning, PhD-level science, and most agentic benchmarks. Each company would tell you the metrics where it leads are the ones that count. Only one of them just demonstrated it can double its weakest metric in ninety days.
The Breakdown
- Gemini 3.1 Pro scored 77.1% on ARC-AGI-2, a 2.5x reasoning jump from 31.1% in three months
- Google distilled Deep Think capabilities into the production model in seven days, the fastest lab-to-production cycle yet
- Pricing unchanged at $2/$12 per million tokens, with Google using the model as a loss leader for its platform
- Anthropic's coding lead over Gemini has shrunk to 0.2 percentage points on SWE-Bench Verified
The seven-day factory
Here is the production timeline. November: Google ships Gemini 3 Pro. December: Gemini 3 Flash. February 12: a major Deep Think update. February 19: those Deep Think capabilities land in the production model as Gemini 3.1 Pro.
Four iterations in three months. The last two separated by one week.
Google has never done a .1 increment on Gemini before. Previous mid-cycle refreshes were .5 releases, typically landing around May for Google I/O. The compressed numbering tells you something about what happened inside the organization. Google didn't plan this cadence on a product roadmap twelve months ago. It discovered it could move faster and adjusted the versioning to match. That's an emboldened company, one that smells an opening and accelerates into it.
The industry calls this distillation. Build advanced reasoning in a specialized thinking model. Validate those capabilities on hard benchmarks. Then fold the gains back into the general-purpose model that millions of people actually use. OpenAI executed this playbook when o1's capabilities fed into GPT-5. That process took months. Google compressed it to days.
That compression is the real announcement. A lab that can push breakthroughs from its research track to its production line in a week doesn't need to win every benchmark on every given Tuesday. It needs to improve faster than anyone can respond. Right now, no one is responding faster.
Choosing the battlefield
The traditional benchmarks tell Google's story well enough. ARC-AGI-2 at 77.1%, up from 31.1%. GPQA Diamond at a record 94.3%. Humanity's Last Exam at 44.4%, clearing Claude Opus 4.6's 40.0% and GPT-5.2's 34.5%. On SWE-Bench Verified, the coding test that Anthropic has owned for the better part of a year, Google closed to within two-tenths of a percentage point. 80.6% versus 80.8%. Practically a rounding error.
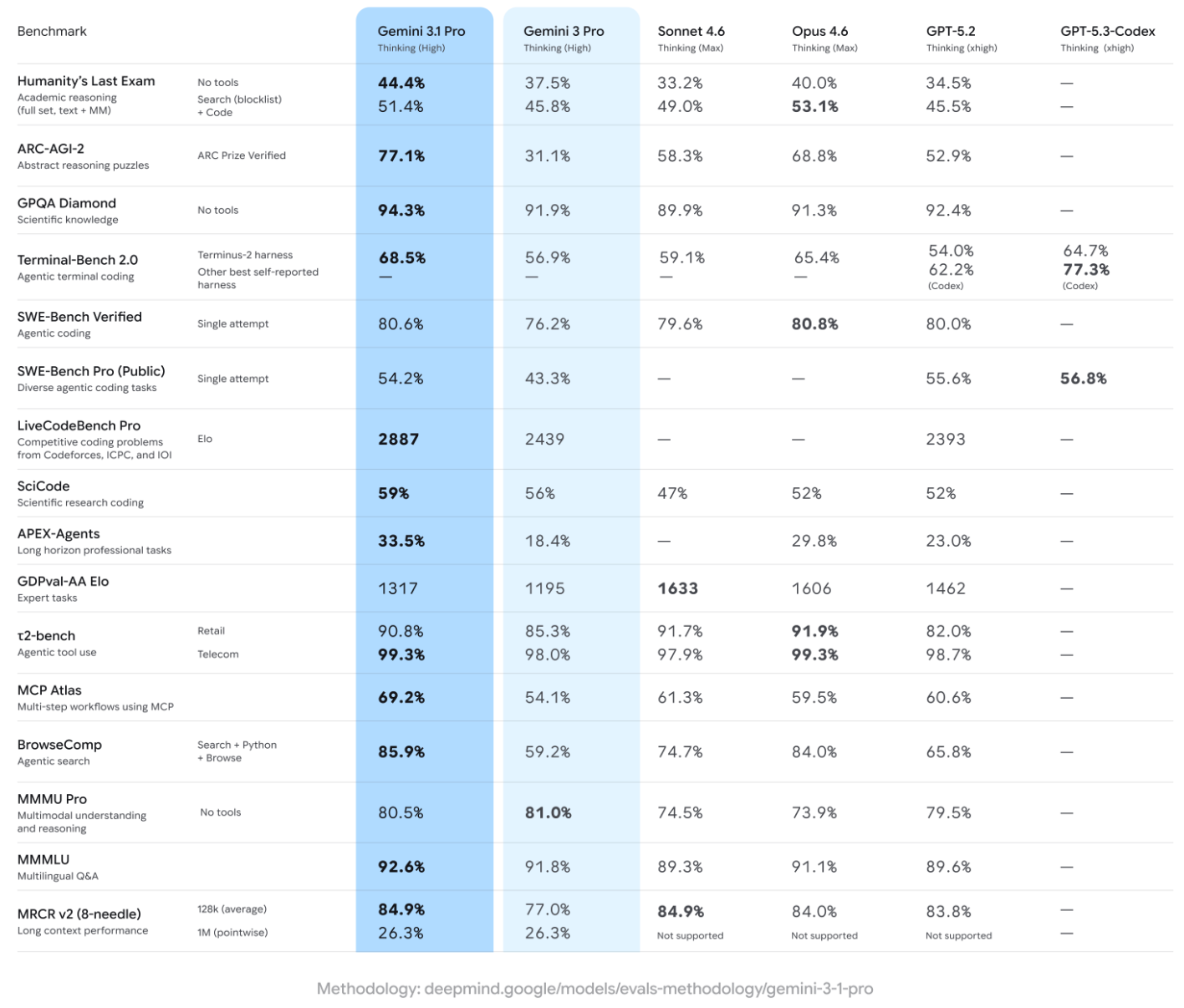
But look at the other half of the table. BrowseComp jumped from 59.2% to 85.9%. APEX-Agents went from 18.4% to 33.5%, nearly doubling. Terminal-Bench climbed from 56.9% to 68.5%.
You've probably never heard of most of those tests. That's the point.
Half the evaluations in this release measure agentic performance: how well a model can autonomously browse the web, execute multi-step professional tasks, and manage long-horizon workflows without human intervention. These benchmarks didn't exist twelve months ago. Google is selecting which contests matter. And it's selecting the ones where enterprise budgets sit. Autonomous agents that configure dashboards from live telemetry feeds. Software that resolves engineering tickets while the team sleeps.
The competitive picture depends entirely on which test you examine. On ARC-AGI-2 reasoning, Google leads Opus 4.6 by over eight points, 77.1% to 68.8%. Anthropic still edges ahead on coding by two-tenths. Humanity's Last Exam, the hardest general knowledge test currently available, goes to Google at 44.4% against Opus 4.6's 40.0%. Agentic browsing and professional tasks? Google has no close competitor at all. Each lab can construct a narrative where it's winning. The question is which narrative enterprise buyers believe.
But the oldest and most human measurement tells a contradictory story. On the Arena leaderboard, where real users vote on outputs they prefer, Claude Opus 4.6 still leads Gemini 3.1 Pro by four points for text and by wider margins for code. JetBrains reports 15% quality gains with 3.1 Pro. Databricks calls it "best-in-class" on its internal reasoning benchmark. Yet vibes and benchmarks are different animals, and they don't always travel together.
Stay ahead of the curve
Strategic AI news from San Francisco. No hype, no "AI will change everything" throat clearing. Just what moved, who won, and why it matters. Daily at 6am PST.
No spam. Unsubscribe anytime.
Google knows this gap exists. The agentic pivot is partly a workaround. If preference is hard to win, compete on measurable task completion instead. Build the tests that reward what your factory produces best. Then let procurement teams run the numbers.
Same price, twice the reasoning
Here's a detail more revealing than any benchmark. Google didn't raise the price.
Gemini 3.1 Pro costs $2 per million input tokens and $12 per million output. Identical to Gemini 3 Pro. Same context window: one million tokens in, 64,000 out. Cached input pricing drops to $0.20 per million tokens, making repeated production queries extraordinarily cheap. Google shipped a model with doubled reasoning capability at zero additional cost. In any other industry, that's a 50% price cut.
On the Pareto frontier of performance versus cost, 3.1 Pro now sits alone in the position every enterprise buyer wants. It scores 77.1% on ARC-AGI-2 at $0.96 per task. Competitors cluster below 60% at comparable or higher price points. Deep Think pushes to 84.6% but at significantly greater inference cost. The math is hard to argue with, and procurement teams are paid to do exactly this kind of math.
Google can sustain this pricing because the model is not the product. The distribution network is. Gemini powers the consumer app, NotebookLM, Vertex AI for enterprise, the Antigravity agentic development platform, Android Studio, Gemini CLI, and Gemini Enterprise. Through a multi-year partnership, it will serve as the cloud foundation for Apple's rebuilt Siri in iOS 27.
Let that register. Google's reasoning engine will power the default assistant on both Android and iPhone. The model is a loss leader. Distribution is the moat.
For Anthropic, this creates an uncomfortable equation. Its coding lead over Gemini sits at 0.2 percentage points on SWE-Bench Verified. Its advantage on the Arena vibes leaderboard is real but hard to sell to CFOs. If you're an enterprise CTO comparing vendors, and one of them already controls the platform your workforce uses eight hours a day while the other requires a separate API integration and billing relationship, that fraction of a coding point won't swing the deal. Anthropic looks increasingly anxious, a company selling premium components to a competitor that manufactures the whole car.
Why the lead keeps shrinking
Google's improvement velocity creates structural problems for everyone else.
The distillation pipeline shrinks the shelf life of any technical lead. Anthropic ships a model that edges ahead on coding today. Google's factory produces a counterpunch in weeks, not quarters. OpenAI announces a reasoning breakthrough in March. By April, Google has matched it and shipped the results to Gemini's consumer base. The cycle from specialized research model to general production model, which once took an entire product cycle, now takes one sprint. A lead that lasted six months a year ago now lasts six weeks. The monetization window for any single advantage keeps collapsing.
The agentic framing redirects how enterprise customers evaluate vendors. IT buyers used to compare models on summarization quality and question-answering speed. The new benchmarks measure something different. In one demo, 3.1 Pro pulled live telemetry from the International Space Station and built a tracking dashboard on the spot. No one touched a keyboard. Google's APEX-Agents score jumped 82% from last quarter, giving its sales team ammunition that competitors lack. Whether those numbers translate to production reliability remains an open question. But the buying conversation has already shifted.
And the Apple deal changes the distribution calculus in ways that haven't fully registered. OpenAI captured consumer mindshare with ChatGPT. Anthropic built developer loyalty through Claude Code and API ergonomics. Both advantages require users to seek them out. Google's integration works at the infrastructure layer. Through its Apple partnership, Gemini will power Siri on hundreds of millions of iPhones by next year. You don't choose infrastructure. It's just there when you pick up the phone.
The factory floor
Google's competitors will match these specific benchmarks within months. They always do. GPT-5.3 is in the pipeline. Anthropic will ship the next Claude. The numbers on the ARC-AGI-2 leaderboard will reshuffle by summer.
But the production system that generated those numbers, research to product in seven days, four releases in ninety days, reasoning doubled at identical cost, that's the harder thing to replicate. It requires tightly coupled research and engineering teams, a distillation process that works reliably under pressure, and the institutional nerve to ship so fast that your own models cannibalize each other before competitors can finish benchmarking the previous release.
The AI race used to be about who builds the best model. Quietly, without anyone sending a memo, it became about who builds the best factory. Google just opened the doors. Skip the shiny car on the turntable. Look at the production line behind it, already retooling for the next version, already making the model you're evaluating today obsolete before you finish the procurement review.
Frequently Asked Questions
What is ARC-AGI-2 and why does Google's score matter?
ARC-AGI-2 tests whether AI models can solve logic patterns they never encountered during training. Gemini 3.1 Pro's 77.1% more than doubled the previous Gemini 3 Pro result of 31.1% and leads Claude Opus 4.6 at 68.8%. The benchmark was designed to resist memorization, making the jump significant for measuring genuine reasoning.
How does Google's distillation pipeline work?
Google builds advanced reasoning in a specialized model like Deep Think, validates it on benchmarks, then folds those gains into the general-purpose production model. The latest cycle took seven days. OpenAI used a similar approach with o1 feeding GPT-5, but that took months.
How does Gemini 3.1 Pro pricing compare to competitors?
It costs $2 per million input tokens and $12 per million output, unchanged from Gemini 3 Pro. Cached input drops to $0.20 per million. At $0.96 per ARC-AGI-2 task, it offers the best reasoning-to-cost ratio among frontier models. Context window stays at one million input and 64,000 output tokens.
Will Gemini 3.1 Pro power Apple's Siri?
Through a multi-year partnership, Google's Gemini models will serve as the cloud foundation for Apple's rebuilt Siri in iOS 27. Google's reasoning engine will power the default assistant on both Android and iPhone, giving it infrastructure-level distribution across both major mobile platforms.
Where does Anthropic's Claude still beat Gemini?
Claude Opus 4.6 leads on the Arena leaderboard by four points for text and wider margins for code, where real users vote on preferred outputs. On SWE-Bench Verified, Anthropic leads 80.8% to 80.6%. Claude also scores higher on the CAIS safety assessment. The gaps are narrowing but Anthropic retains edges in coding and user preference.




Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


