
💡 TL;DR - The 30 Seconds Version
🚀 OpenAI launched GPT-5 with three model tiers (main, mini, nano) using a complex routing system that picks different models based on query complexity.
📊 GPT-5 scores 74.9% on bug-fixing benchmarks and 96.7% on tool-calling tests, using 22% fewer tokens than previous models for the same tasks.
🔓 Security remains broken: 56.8% of prompt injection attacks still succeed when attackers get 10 tries, making it unsafe for high-stakes applications.
💰 Pricing starts at $1.25 per million input tokens, but invisible reasoning tokens cost $10 per million output—bills multiply at higher reasoning levels.
🔍 The API hides all thinking processes, forcing developers to pay for reasoning they can't see or turn it off entirely for transparency.
⚡ GPT-5 represents optimization over innovation—better at everything but still fundamentally limited by the same architectural and security constraints as 2024 models.
OpenAI dropped GPT-5 after weeks of preview testing. The model beats its predecessors on nearly every benchmark, but the real story isn't in the marketing slides—it's in what happens when you actually use it.
Simon Willison, who got two weeks of early access, puts it bluntly: "It rarely screws up and generally feels competent." That's damning with faint praise for what OpenAI calls a major step toward AGI. But after digging through the system card and running tests, Willison's assessment makes sense. This isn't a breakthrough. It's an optimization.
The architecture reveals the first compromise. ChatGPT doesn't run one GPT-5 model—it runs three different ones with a router deciding which to use based on your question. Ask something simple, get the fast model. Ask something complex, trigger the reasoning model. Hit your usage limits? You're stuck with a "mini version" that OpenAI barely mentions in the documentation.
The Performance Story
Let's talk numbers. GPT-5 scores 74.9% on SWE-Bench Verified, where models fix real software bugs. That's up from o3's 69.1%, but here's what matters more: GPT-5 does it with 22% fewer output tokens and 45% fewer tool calls. It's not just smarter—it's more efficient.
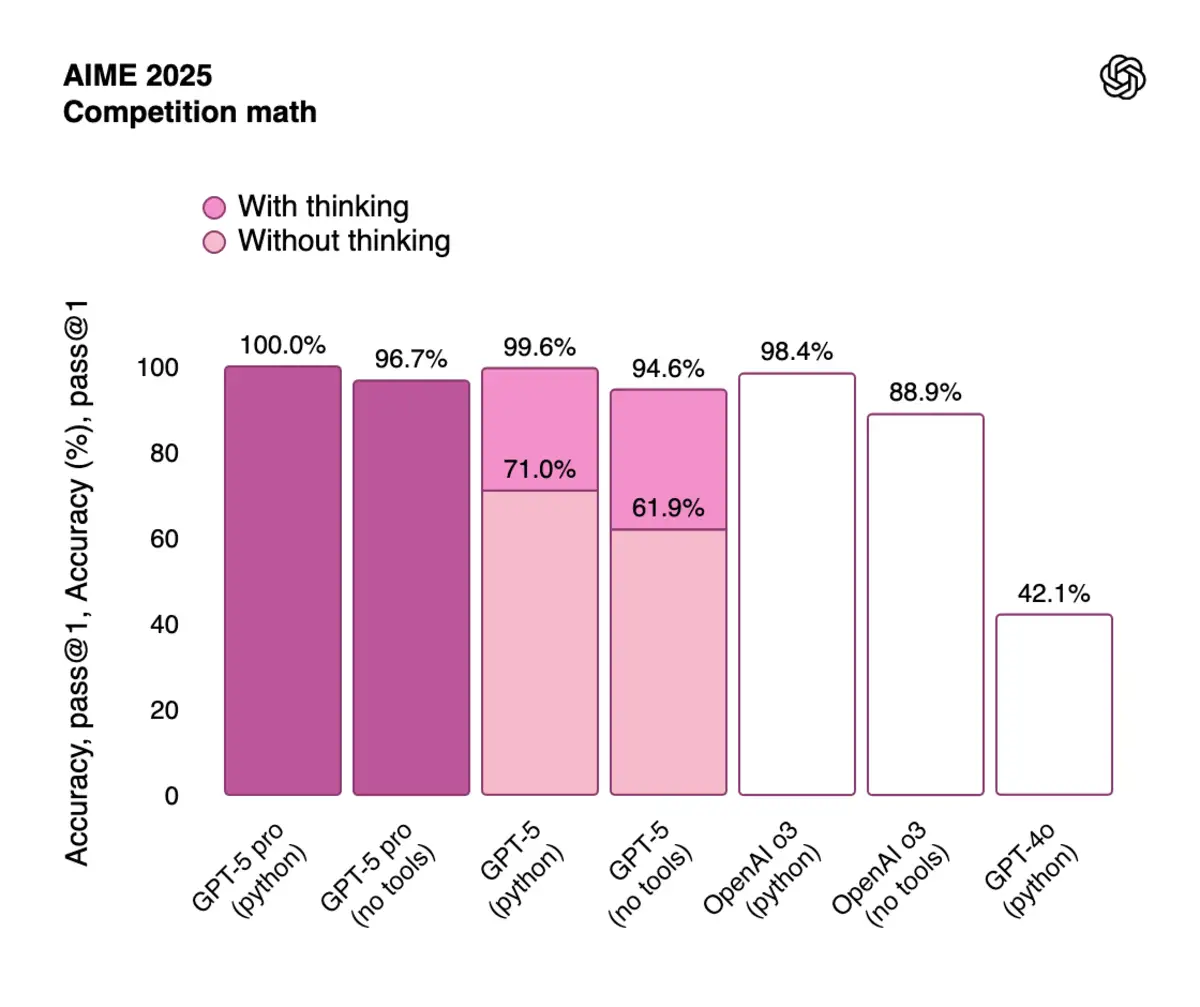
The model crushes tool-calling benchmarks too. On τ2-bench telecom, a test published just two months ago, GPT-5 hits 96.7%. When that benchmark launched, no model scored above 49%. The jump comes from better error handling and the ability to chain dozens of tool calls without losing track.
Coding feels different with GPT-5. Cursor calls it "the smartest model we've used." Windsurf reports half the tool-calling error rate compared to other models. But these endorsements come from companies with financial ties to OpenAI's success. Independent developer Simon Willison offers a cooler take: it's "very sensible" and he hasn't felt the need to try other models. Not exactly revolutionary.
The Architecture Problem
The three-tier system (GPT-5, mini, nano) with four reasoning levels (minimal, low, medium, high) creates a maze of options. Each combination performs differently. CharXiv visual reasoning barely improves beyond low reasoning effort, but other tasks need high settings to shine. Developers must run experiments to find the right combo for each use case.
The API pricing starts at $1.25 per million input tokens for full GPT-5—half what GPT-4o costs. But those invisible reasoning tokens count as output at $10 per million. Run it at high reasoning effort and watch your bills multiply. The nano version costs just $0.05 per million input tokens, but check that SWE-bench score: 54.7% versus the full model's 74.9%. You get what you pay for.
OpenAI hides the thinking process completely in the API. You see a delay, then get an answer. No insight into how the model reached its conclusion. They even added a "minimal" reasoning option that skips most thinking just so developers can see something happening. It's absurd—we're turning off the main feature just to get transparency.
The Security Disaster
Here's where things get ugly. OpenAI tested GPT-5 against prompt injection attacks. The result? A 56.8% attack success rate when attackers get ten tries. That's better than Claude's 60-something percent and much better than other models hitting 70-90%. But "better" doesn't mean "good."
Think about what 56.8% means. More than half of determined attacks still work. If you're building anything that handles sensitive data or makes real decisions, that's terrifying. OpenAI's system card admits this plainly: "Don't assume prompt injection isn't going to be a problem for your application just because the models got better."
The company claims to have done "over 5,000 hours" of safety testing. They developed something called "safe-completions" where the model gives partial answers to potentially dangerous questions instead of refusing outright. A chemistry student asking about combustion gets a high-level explanation. Someone building a bomb gets the same thing. The model can't tell the difference.
The Hallucination Question
OpenAI says GPT-5 makes 80% fewer factual errors than o3. On LongFact benchmarks, the hallucination rate drops to around 1% for GPT-5 versus 5.2% for o3. Impressive, until you read the fine print: "As with all language models, we recommend you verify GPT-5's work when the stakes are high."
Willison hasn't spotted a single hallucination in two weeks of testing. But he notes the same is true for Claude 4 and o3 recently. The entire class of 2025 models has gotten better at not making stuff up. GPT-5 isn't special here—it's just keeping pace.
The Context Window Game
GPT-5 handles 272,000 input tokens and 128,000 output tokens. On long-context retrieval tests, it maintains accuracy better than previous models as documents get longer. At maximum length, GPT-5 correctly retrieves information 86.8% of the time versus o3's 55%.
But context isn't free. Process a long document at high reasoning effort and you're burning through tokens at both ends—input costs for the document, output costs for all that invisible thinking. The pricing model punishes exactly the use cases where GPT-5 shines brightest.

Sam Altman compared GPT-5's improvement to the iPhone getting a Retina display. But Retina displays were immediately, obviously better. GPT-5 requires spreadsheets to figure out which model variant and reasoning level to use, calculators to predict costs, and faith that the hidden thinking process is worth the price.
Why this matters:
• GPT-5's real innovation isn't intelligence—it's the complex routing system that picks different models based on your query, creating an illusion of consistency while hiding massive architectural complexity
• At a 56.8% prompt injection success rate, GPT-5 remains fundamentally unsafe for high-stakes applications despite being the best performer in its class—security through "least terrible" isn't security
❓ Frequently Asked Questions
Q: How much will GPT-5 cost me for a typical coding task?
A: A 10,000-token coding task costs about $0.11 with GPT-5 at medium reasoning. The same task with nano costs $0.004. But GPT-5 solves 74.9% of bugs correctly versus nano's 54.7%, so you might spend more fixing nano's mistakes.
Q: What exactly are these "invisible reasoning tokens" I'm paying for?
A: GPT-5 internally generates step-by-step reasoning before answering, like showing work on a math problem. You pay $10 per million tokens for this thinking, but OpenAI doesn't show you what it thought. ChatGPT users see summaries; API users see nothing.
Q: Which version should I use - GPT-5, mini, or nano?
A: GPT-5 handles complex coding and analysis. Mini works for standard business tasks at 1/5 the price. Nano suits simple queries at 1/25 the cost. On coding benchmarks: GPT-5 scores 74.9%, mini gets 71%, nano manages 54.7%.
Q: How does GPT-5 compare to Claude 4 and Gemini 2.5?
A: GPT-5 costs $1.25 per million input tokens versus Claude Sonnet 4's $3.00 and Gemini 2.5 Pro's $1.25-$2.50. On security, GPT-5's 56.8% vulnerability rate beats Claude's 60%+ and Gemini's 85%. All three handle 200,000+ tokens.
Q: What's this "safe completions" feature and when does it kick in?
A: Instead of refusing sensitive questions, GPT-5 gives partial answers. Ask about combustion energy for homework, get details. Ask the same question suspiciously, get high-level info only. The model guesses your intent but often guesses wrong.
Q: Can GPT-5 actually process 272,000 tokens? How much text is that?
A: Yes, that's roughly 200,000 words or a 400-page book. But accuracy drops with length—GPT-5 retrieves correct info 95% of the time at 128,000 tokens, 87% at maximum length. You pay full price for every token regardless.
Q: Why does the SVG pelican test matter for a language model?
A: Creating visual code from text instructions tests spatial reasoning and detail tracking. GPT-5 draws recognizable pelicans with proper bicycle frames. Mini adds weird features like double necks. Nano produces circles and random lines. It's a quick visual benchmark for model degradation.
Q: When can regular ChatGPT users access GPT-5 without hitting limits?
A: Free users get GPT-5 now but hit undisclosed caps quickly, then drop to mini versions. Plus ($20/month) users get "significantly higher" limits. Pro ($200/month) gets unlimited GPT-5 access plus GPT-5-pro with extended reasoning.

Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


