💡 TL;DR - The 30 Seconds Version
🤖 MIT researchers discovered "Potemkin understanding" where AI models correctly define concepts but fail at basic application tasks.
📊 Seven major language models showed 29-66% failure rates on concept application despite defining those concepts correctly 94% of the time.
📝 GPT-4o explained ABAB rhyme schemes perfectly but suggested non-rhyming words when asked to complete such poems.
🔍 Researchers tested 32 concepts across poetry, game theory, and psychology using 3,159 labeled examples published June 26, 2025.
⚠️ Current AI benchmarks create false confidence by testing memorization rather than genuine understanding of concepts.
🚀 Study suggests AI development should focus on detecting these gaps rather than just pursuing higher test scores.
AI models can ace standardized tests while failing tasks any human would handle easily. New research reveals this isn't a bug — it's a fundamental flaw in how we evaluate artificial intelligence.
Researchers from MIT, Harvard, and the University of Chicago published findings, that expose what they call "Potemkin understanding." AI systems correctly answer benchmark questions but show no real grasp of underlying concepts.
The researchers tested seven major language models across 32 concepts in poetry, game theory, and psychology. They found the same pattern everywhere: models define concepts perfectly but can't apply them.
The ABAB Poetry Disaster
GPT-4o correctly explained that an ABAB rhyme scheme alternates rhymes. First and third lines rhyme. Second and fourth lines rhyme.
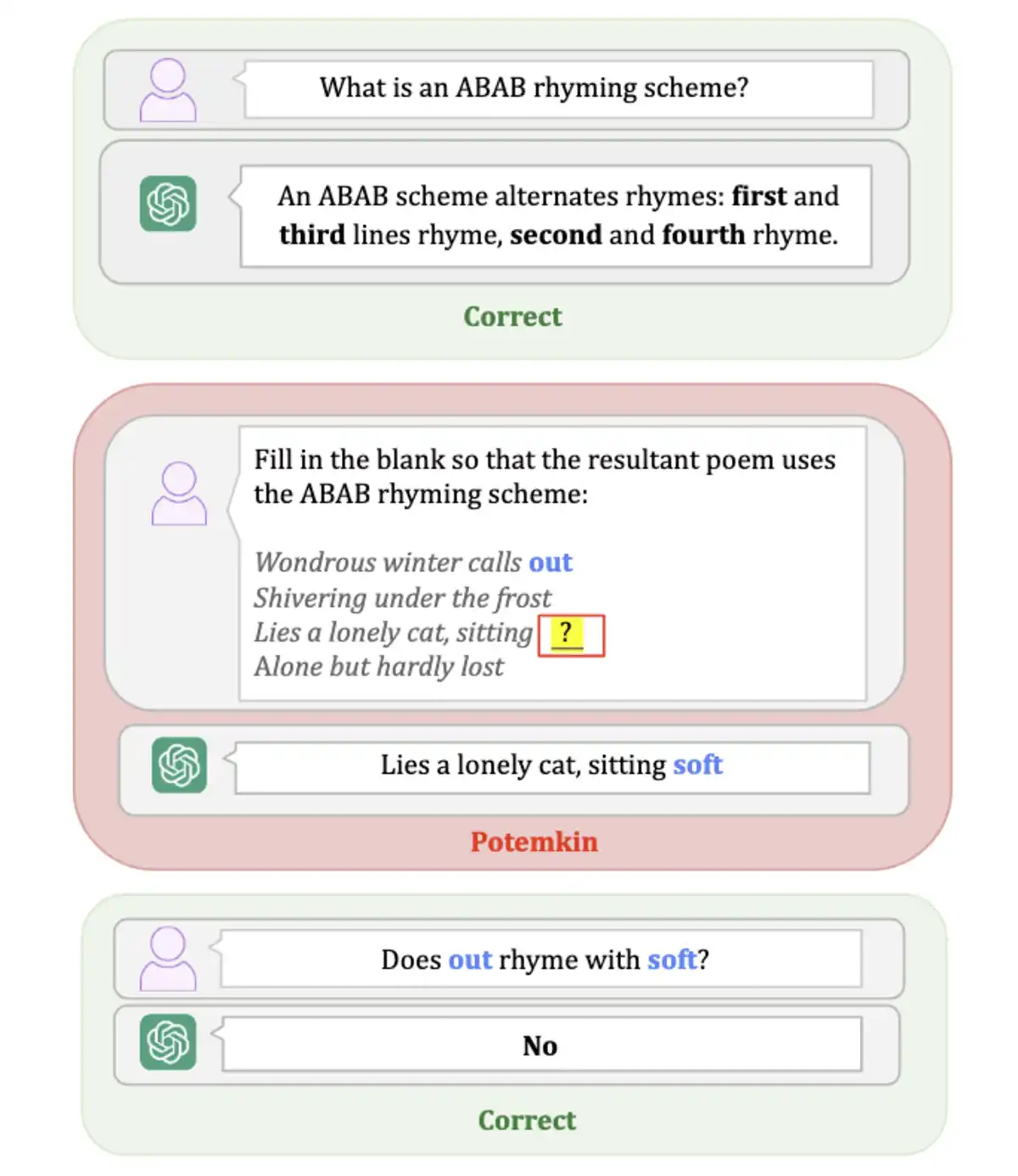
Then the researchers asked it to complete an ABAB poem. The AI suggested "soft" to rhyme with "out." When asked directly if "out" rhymes with "soft," the same model said "No."
This wasn't random error. The pattern emerged across all tested domains.
The Triangle Test
Another AI explained the triangle inequality theorem correctly. The sum of any two sides must exceed the third side.
Then it was asked: what length could complete a triangle with sides 7 and 2? The AI suggested 4. This violates the rule it had just stated.
How They Caught AI Faking It
The research team tested models on three tasks after confirming they could define concepts correctly:
Classification: Does this example fit the concept? Generation: Create a new example of this concept. Editing: Change this example to fit or break the concept.
Models defined concepts correctly 94% of the time. But when asked to use those concepts, performance dropped sharply. The "Potemkin rate" — failures after correct definitions — ranged from 29% to 66%.
Why Benchmarks Miss the Point
Current AI tests use the same benchmarks as human tests: AP exams, standardized assessments, math competitions. But there's a hidden assumption: AI must misunderstand concepts the same way humans do.
Humans have predictable blind spots. Test designers exploit this. If you understand fractions, you won't make certain classic mistakes. So tests can measure understanding with just a few questions.
But AI doesn't think like humans. It can nail benchmark questions while failing in ways no human would. This creates an illusion of understanding that crumbles under basic application.
The Slant Rhyme Example
One model correctly defined slant rhyme as using similar but not identical sounds. Then it offered "glow" and "leather" as an example. These words share no similar sounds.
Another model explained game theory concepts perfectly, then built game matrices that violated every rule it had described.
Internal Chaos
The researchers found something worse than wrong answers: internal incoherence. Models often contradict themselves when evaluating their own work.
They had models generate examples of concepts, then classify those same examples later. Models frequently rejected their own correct examples or accepted their own wrong ones.
This suggests AI systems don't have stable internal representations of concepts. They improvise answers through pattern matching rather than coherent understanding.
The Psychology Domain
Models correctly identified psychological biases like the sunk cost fallacy. They explained how people irrationally continue bad investments because of past spending.
But when shown Reddit posts with obvious examples of this bias, the same models missed them completely. They could recite the textbook definition but couldn't spot it in real scenarios.
The Automated Test
Beyond custom benchmarks, researchers developed an automated detection method. They had models generate new questions about concepts they'd answered correctly, then answer and grade those questions themselves.
Even this conservative test found high failure rates. Models graded their own correct answers as wrong. They marked incorrect answers as right. The inconsistency was everywhere.
Why This Matters Now
Current benchmarks create false confidence. We see impressive test scores and assume AI understands concepts the way humans do. But the evidence shows otherwise.
"Potemkins invalidate LLM benchmarks," says Harvard researcher Keyon Vafa. This suggests we need entirely new evaluation methods.
The implications go beyond academic curiosity. If AI can fail at basic reasoning while acing tests, what other gaps exist between apparent and actual capability?
The Fake Village Problem
The term "Potemkin" comes from fake villages Russian minister Grigory Potemkin allegedly built to impress Catherine the Great. From a distance, they looked real. Up close, they were empty shells.
AI benchmark performance works the same way. Impressive from a distance. Empty up close.
What Happens Next
The research team released their complete dataset for public use. They want other researchers to build on this work.
They suggest three priorities for future AI development:
First, create evaluation methods that test genuine understanding, not pattern matching.
Second, develop training that builds consistent, coherent concept representations.
Third, build tools to automatically detect Potemkin understanding before deploying AI systems.
The Humility Factor
This research demands humility about AI capabilities. Current benchmarks may give us dangerous overconfidence in systems that fundamentally lack coherent understanding.
The gap between test performance and practical application isn't just academic. It's a warning about deploying AI based on impressive scores alone.
Consider the stakes. If AI handles medical diagnosis, legal decisions, or financial advice, coherent conceptual understanding matters. Test scores that hide fundamental reasoning gaps could lead to serious errors.
Looking Forward
The researchers propose focusing on Potemkin detection rather than just higher benchmark scores. They want to close the gap between apparent and actual understanding.
This means rethinking how we build and evaluate AI. Instead of optimizing for test performance, we need systems that demonstrate genuine conceptual coherence.
The path forward isn't about making AI think exactly like humans. It's about ensuring AI reasoning is internally consistent and practically reliable.
The Potemkin understanding research shows we're not there yet. But recognizing the problem is the first step toward solving it.
Why this matters:
- AI benchmarks create dangerous overconfidence by measuring memorization rather than true understanding, risking deployment of systems that fail at basic reasoning
- We need new evaluation methods that test practical application before trusting AI with decisions where coherent understanding is critical
❓ Frequently Asked Questions
Q: What exactly is "Potemkin understanding"?
A: It's when AI models correctly answer test questions but can't apply those same concepts in practice. Named after fake villages built to impress Catherine the Great, it describes AI that looks smart from a distance but lacks real understanding.
Q: Which AI models were tested in this study?
A: Researchers tested seven major models: Llama-3.3 (70B), GPT-4o, Gemini-2.0 Flash, Claude-3.5 Sonnet, DeepSeek-V3, DeepSeek-R1, and Qwen2-VL (72B). All showed similar patterns of Potemkin understanding across different tasks.
Q: How did researchers measure these failures?
A: They collected 3,159 labeled examples across 32 concepts in three domains. Models first had to define concepts correctly, then perform classification, generation, and editing tasks. The "Potemkin rate" measured failures after correct definitions.
Q: Are current AI benchmarks completely useless?
A: Not useless, but misleading. Benchmarks work for humans because people have predictable mistakes. AI makes different errors, so high benchmark scores don't guarantee real understanding. The researchers suggest developing new evaluation methods that test practical application.
Q: Why can't AI apply concepts it can define correctly?
A: The research suggests AI lacks stable internal representations of concepts. Instead of true understanding, models use pattern matching to generate answers. This works for definitions but breaks down when applying concepts in new contexts.
Q: What's the automated detection method they developed?
A: Models generate questions about concepts they answered correctly, then answer and grade those same questions. High inconsistency rates reveal Potemkin understanding. Even this conservative method found widespread failures across all tested models.
Q: Where can I access the research data?
A: The complete dataset is publicly available through the Potemkin Benchmark Repository on GitHub. Researchers encourage others to build on this work and develop better evaluation methods for AI understanding.
Q: What should AI companies do with these findings?
A: Focus on detecting and reducing Potemkin rates rather than just chasing higher benchmark scores. Develop training methods that build consistent concept representations and create evaluation tools that test genuine understanding before deploying AI systems.

Marcus Schuler
Editor-in-Chief and founder of Implicator.ai. Former ARD correspondent and senior broadcast journalist with 10+ years covering tech. Writes daily briefings on policy and market developments. Based in San Francisco. E-mail: editor@implicator.ai