The race for better AI speech recognition just got more interesting. OpenAI has dropped a suite of new audio models that promise to make those awkward conversations with voice assistants a thing of the past.
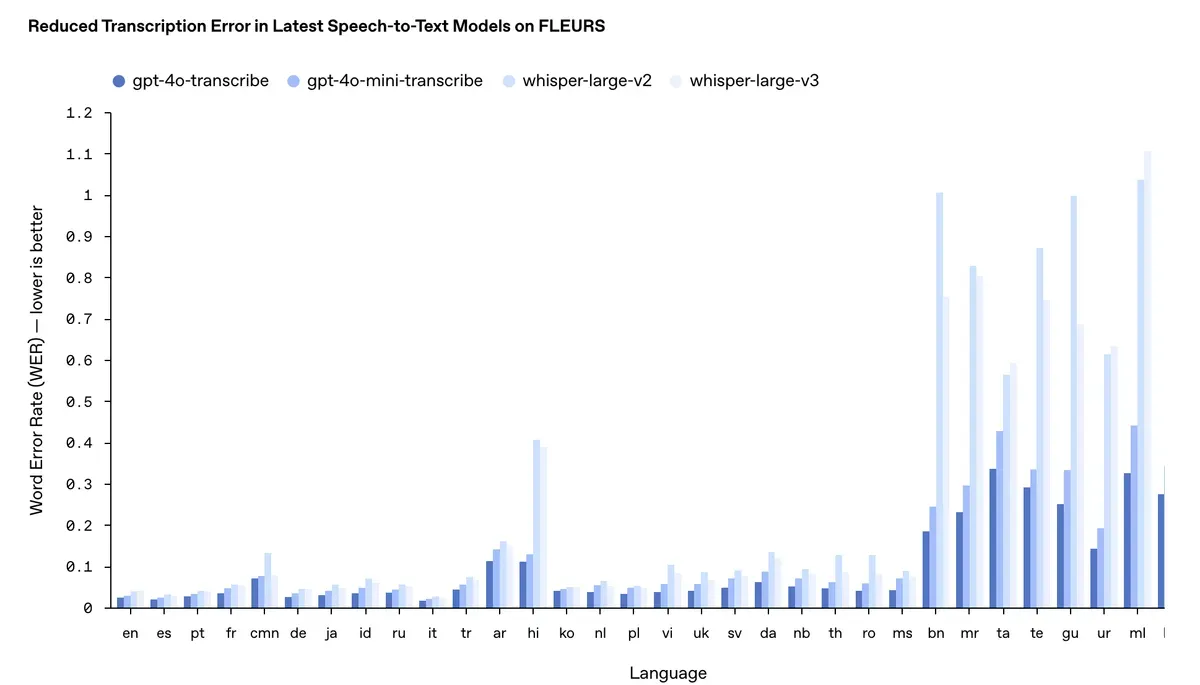
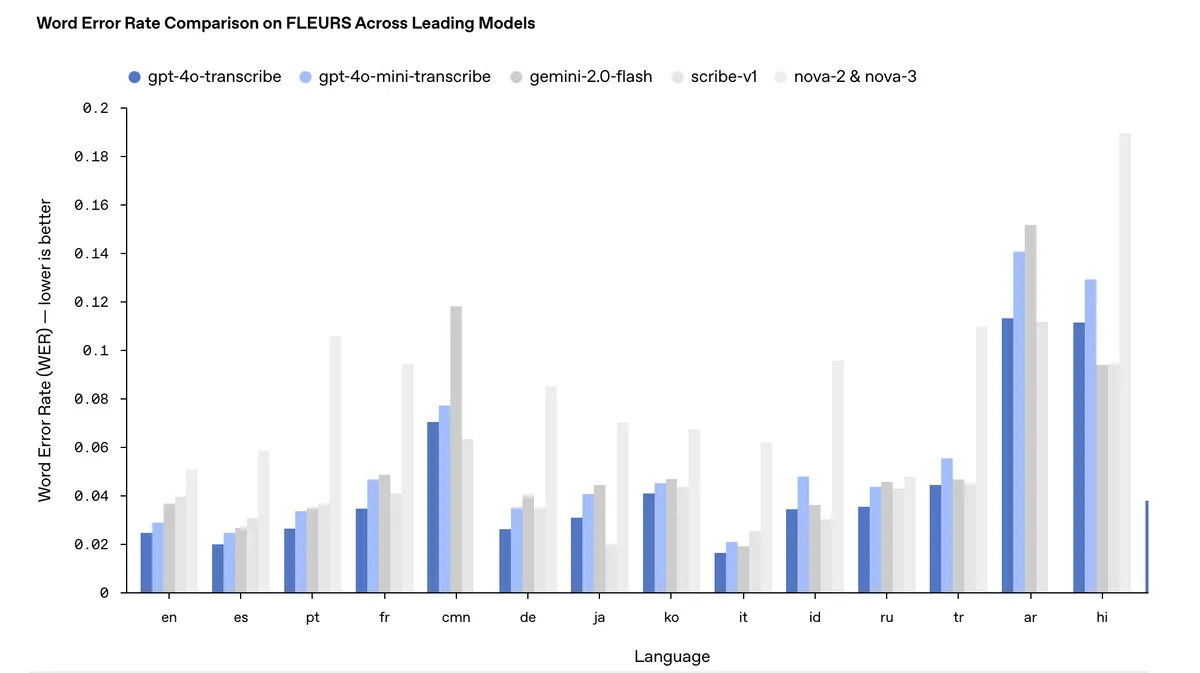
The latest speech-to-text models, gpt-4o-transcribe and its nimbler sibling gpt-4o-mini-transcribe, are flexing some impressive metrics. They're not just marginally better - they're leaving established benchmarks in the dust, especially when dealing with those perennial thorns in the side of speech recognition: accents, background noise, and people who talk faster than startup pitch decks.
But the real showstopper? The new text-to-speech model can take directions. Want your AI to sound like a sympathetic customer service rep instead of a robot reading warranty terms? That's now possible. The gpt-4o-mini-tts model brings personality to synthetic speech, though it's still limited to preset voices - no impersonating celebrities just yet.
The technical heavy lifting behind these improvements reads like a machine learning greatest hits album. OpenAI went all-in on reinforcement learning, creating models that learn from their mistakes instead of just memorizing patterns. They've also mastered the art of model distillation, somehow squeezing brain-sized intelligence into pocket-sized packages.
The benchmarks tell a compelling story. Across multiple languages, the new models consistently outperform their predecessors and competitors. Word Error Rate (WER) - the metric that measures how often these models mess up - has dropped significantly. In plain English: these models are better at understanding plain English (and Spanish, French, German, and dozens of other languages).
This isn't just another incremental update dressed up in marketing speak. The improvements stem from some serious engineering muscle: specialized audio datasets for pretraining, advanced distillation techniques that make smaller models punch above their weight, and a reinforcement learning approach that would make most ML engineers whistle in appreciation.
Developers get immediate access to these models through the API, complete with integration support for the Agents SDK. For those building real-time applications, there's a direct path through the Realtime API. It's like getting keys to a new sports car, complete with driving instructions.
The roadmap ahead includes plans for custom voices - a feature that will undoubtedly raise eyebrows among privacy advocates and creative rights holders. OpenAI acknowledges the ethical tightrope they're walking, promising to engage with policymakers and researchers about the implications of synthetic voice technology.
Most intriguingly, this release hints at broader ambitions in multimodal AI. Video capabilities are on the horizon, suggesting a future where AI agents might see and hear as naturally as they read and write.
Why this matters:
- We're witnessing the quiet death of bad voice recognition. These models don't just incrementally improve on existing tech - they rewrite the rules of human-machine conversation
- The ability to instruct AI on how to speak, not just what to say, marks a subtle but crucial shift in voice interface design. Soon, the most natural-sounding voice in your customer service call might be the AI's
Read on, my dear:
OpenAI: Introducing next-generation audio models in the API

Marcus Schuler
Senior broadcast journalist and former ARD correspondent for Europe's largest public broadcaster. Covering the tech industry from San Francisco for 10+ years. Founded implicator.ai for independent, rigorous AI reporting. E-mail: [email protected]


