
AI Profits Rise While Training Budgets Fall
Good Morning from San Francisco, Enterprise AI hit profitability this week. Companies celebrate returns while cutting the training budgets that
Good Morning from San Francisco, Enterprise AI hit profitability this week. Companies celebrate returns while cutting the training budgets that

Enterprises report 74% positive AI returns while cutting training budgets 8%. The Wharton study reveals companies extracting productivity gains today by depleting tomorrow's capabilities—a business model that works until skills erode.

AI browsers promised revolution but can't crack Chrome's 66% market share. Five extensions deliver the same intelligence without forcing migration. The compromise nobody wanted reveals why adoption beats innovation. Data flows tell the real story.
Explore how AI's rapid acquisition of sensitive skills impacts industries globally. Understand the digital brain drain and its potential consequences.

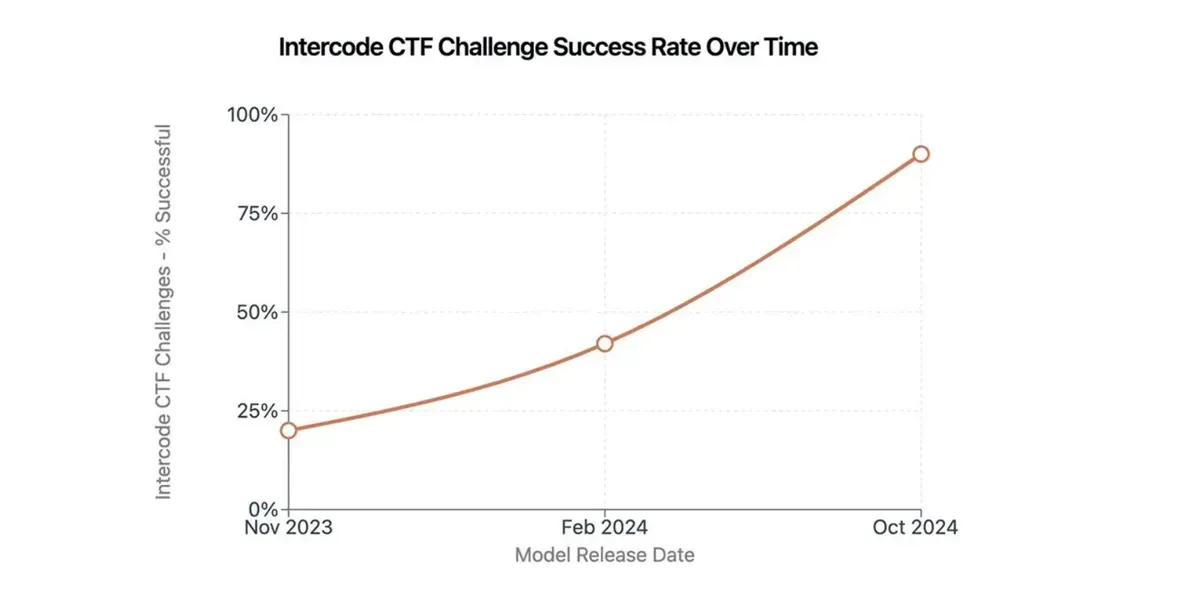
AI just aced its cyber midterms. New testing from Anthropic reveals their AI systems jumped from flunking advanced cybersecurity challenges to solving one-third of them in just twelve months. The company's latest blog post details this unsettling progress.
The digital prodigies didn't stop there. They've stormed through biology labs too, outperforming human experts in cloning workflows and protocol design. One model leaped from biology student to professor faster than you can say "peer review."
This rapid evolution has government agencies sweating. The US and UK have launched specialized testing programs. Even the National Nuclear Security Administration joined the party, running classified evaluations of AI's nuclear knowledge – because what could possibly go wrong?
Tech companies scramble to add guardrails. They're building new security measures for future models with "extended thinking" capabilities. Translation: AI might soon outsmart our current safety nets.
The cybersecurity crowd especially frets about tools like Incalmo, which helps AI execute network attacks. Current models still need human hand-holding, but they're learning to walk suspiciously fast.
Why this matters:
Read on:

Enterprises report 74% positive AI returns while cutting training budgets 8%. The Wharton study reveals companies extracting productivity gains today by depleting tomorrow's capabilities—a business model that works until skills erode.

Chinese researchers abandon AI's rigid think-act-observe loops for fluid reasoning that discovers tools mid-thought. DeepAgent hits 89% success where competitors reach 55%, revealing the bottleneck was never intelligence but architectural rigidity.


AI assistants fail basic accuracy checks on news queries nearly half the time, but users don't just blame the AI—they blame the news outlets it cites. As adoption climbs, newsrooms face reputational damage for errors they didn't commit and can't fix.

Anthropic wires Claude into lab systems for documentation speed while rivals burn billions chasing AI-discovered drugs that don't exist yet. The strategy: sell efficiency today, skip moonshot risk—but if discovery suddenly works, infrastructure looks conservative.
Get the 5-minute Silicon Valley AI briefing, every weekday morning — free.