


Anthropic's Claude chatbot suffered its third outage in March on Monday, with more than 6,800 users reporting failures on Downdetector by 1:03 p.m. Pacific time. Both the Opus and Sonnet models returned the same blank wall, API Error 500 messages filling screens across the web interface, Claude Code, and the mobile app. Anthropic confirmed "elevated errors" on its status page but offered no explanation for the root cause.
The timing was brutal. One day earlier, Anthropic had begun doubling usage limits for all Claude models during off-peak hours, a promotion running through March 27 designed to pull more users onto the platform. Hours later, those doubled limits were irrelevant. The service was choking under its own weight.
The Breakdown
- Claude suffered three outages in 17 days (March 3, 16, 17), peaking at 6,800 Downdetector reports on March 17.
- Both Opus and Sonnet returned API Error 500 globally, hitting paid users despite Anthropic claiming only free tier impact.
- Outage struck one day after Anthropic doubled usage limits, raising questions about capacity and infrastructure maturity.
- Claude Code developers were stranded mid-project, exposing single-vendor dependency risk across engineering teams.
Three outages, zero explanations
March has been punishing for Anthropic's infrastructure. Claude went down on March 3, when the company posted that it was investigating "elevated errors" affecting the chatbot, Opus 4.6, Claude Console, and Claude Code. It happened again on March 16. Then again on March 17. Each time, the status page acknowledged problems. Each time, the root cause went undisclosed. No post-mortem. No public engineering blog. Just the same vague language recycled across three incidents in 17 days.
StatusGator has been tracking Claude since mid-2024. In February, the monitoring service logged more than twenty-one thousand incidents for Claude alone. Most were brief hiccups, not full blackouts. But twenty-one thousand of anything in a single month paints a specific picture: a platform running persistently close to its red line.
The March 17 incident hit the hardest. Downdetector logged 6,800 complaints at peak, with 44 percent of reports centered on Claude Chat. Significant numbers also targeted Claude Code and the mobile app. The disruption crossed borders, with users in the United States, United Kingdom, India, and Japan all posting the same API Error 500 messages on X.
API Error: 529 {"type":"error","error":{"type":"overloaded_error","message":"Overloa
ded"},"request_id":"req_011CZAZ2dWcmy9icRLWbf"}
Anthropic's status page told a tidy story. The problem had been identified. A fix was being implemented. Only free Claude.ai users were affected. That last claim didn't survive contact with reality. Paid subscribers posted screenshots of the same 500 errors within the hour. One developer shared the full error payload on X, complete with request ID, showing the failure was consistent across accounts and sessions. Another noted that Claude and Cowork, Anthropic's desktop automation tool, were both dead simultaneously.
"Sonnet 4.6 is down. I use this for health, fitness, and nutrition coach agent and it's still not working for me even though the Claude Status website says it's only affecting free users," posted @dansemperepico on X.
Anthropic never corrected its status page to reflect the broader impact. The gap between what the company communicated and what users experienced should make anyone building on the platform nervous.
Developers got stranded mid-commit
Claude Code users were the loudest group during the outage, and for good reason. These are developers running Anthropic's command-line tool for agentic coding tasks, people mid-commit, mid-debug, mid-refactor. When Claude Code returns a 500, the terminal just stops. No graceful degradation, no fallback model. The cursor blinks at nothing.
"Claude Code is down, basically a snow day," posted @thejeneshnapit on X, alongside a screenshot of the frozen terminal.
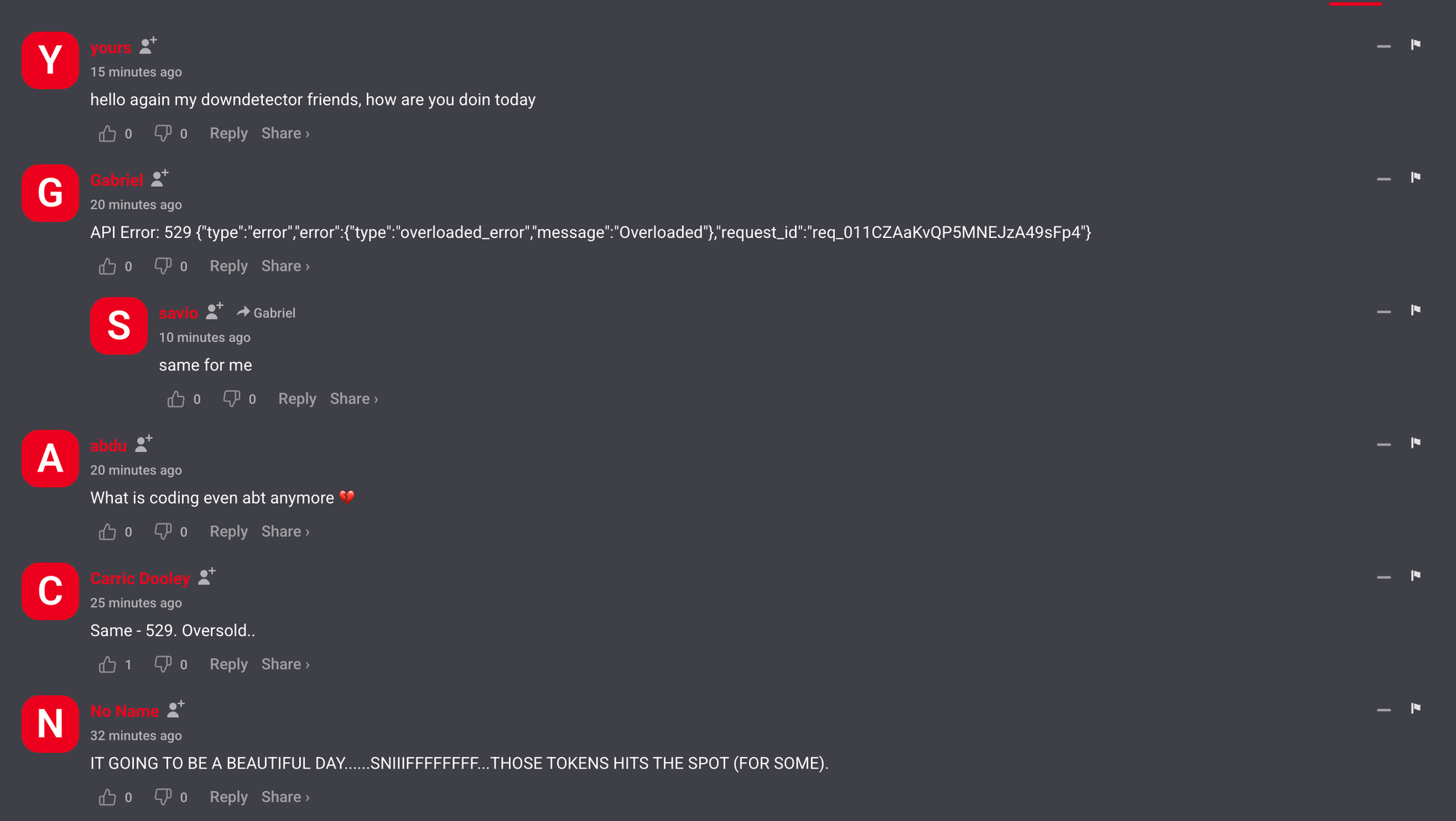
Snow day. That framing captures something real. Developers have woven Claude into their daily workflow so deeply that an outage doesn't slow the work. It halts it. Twelve months back, a dead AI assistant meant Stack Overflow tabs and manual debugging. A hassle, sure. Not a crisis. Now? Sitting idle. Staring at a terminal that won't respond. Waiting for servers in a data center you've never seen to come back online.
The dependency runs deeper than convenience. Developers who adopted vibe coding workflows over the past year restructured how they approach problems entirely. They prompt first, code second. When the prompting layer vanishes, the methodology collapses with it. That's not a productivity dip. That's a workflow crisis.
And it extends beyond individual developers. Teams that integrated Claude Code into their CI pipelines or code review processes discovered Monday that a single vendor's API failure could stall an entire engineering organization. One user on X described being "mid-project without AI at all" when a single bug drove them to Claude, only to find the service already down. Self-reliance, then dependency, then abandonment. That arc says something about how far these tools have burrowed into daily work. Infrastructure teams have a name for this pattern. Single-vendor risk. Ask any platform lead, they'll tell you it's the thing they build entire careers around avoiding.
What Users Said
From Hacker News, Reddit r/ClaudeCode, and Downdetector on March 17/18, 2026
"Have they tried asking Claude to fix it no mistakes?"
tills13 on Hacker News
"this explains the 98% uptime"
kylehotchkiss on Hacker News
"hello again my downdetector friends, how are you doin today"
yours on Downdetector
"They get less sympathy when a lot of their high profile employees talk about using Claude to write 100% of their code and yet Claude Code has loads of issues and their services go down every 10 minutes."
csto12 on Hacker News
"Seems to be inevitable when you write all your code with AI"
verzali on Hacker News
"Same here, I'll tell my boss I'm taking the day off"
bat_ffs on Reddit r/ClaudeCode
"Same - 529. Oversold.."
Carrie Dooley on Downdetector
"Unfounded speculation but it's curious that it's soon after enabling 1M context tokens on the default plan. I wonder if there are some long-tail load ramifications of this pricing change."
cronin101 on Hacker News
"and it's down againn, thanks for taking my money"
savio on Downdetector
"So far, Opencode with GPT-Codex is doing a fantastic job."
YuriM on Downdetector
The fail whale is back, just without the whale
If you were on Twitter between 2008 and 2013, you know exactly what the fail whale looked like. A goofy cartoon whale getting hoisted into the sky by birds. It showed up whenever the servers buckled. Twitter was growing faster than its pipes could carry, and somewhere along the way the whale became the accidental mascot for all of it. Users complained. Users also waited. The product was too good to leave, even when it fell over three times in a week.
Anthropic is living through its own fail whale moment now. Claude reportedly topped App Store charts in early March. Opus 4.6 launched last month to strong reviews. The company doubled usage limits to attract even more traffic. And then the platform buckled. Three times in the same month.
The pattern is familiar because it's structural. Every consumer technology platform that achieves rapid adoption hits this exact wall. The architecture that handles a million users can't handle ten million. The caching layer that survived Tuesday's traffic chokes on Wednesday's. The product scales first because that's what attracts users. The infrastructure scales second because that's what keeps them. Outages live in the gap between those two timelines.
Twitter eventually retired the fail whale. Not because someone shipped a hotfix, but because the company spent years rewriting its architecture from Ruby on Rails to a custom JVM stack, rebuilding caching layers, rethinking how it handled concurrent connections. The whale was a symptom. The cure was boring, expensive infrastructure work that took the better part of five years.
Anthropic doesn't have a cartoon whale. It has a status page that reads "elevated errors" while six thousand users stare at 500 messages. The aesthetics differ. The underlying condition is identical.
Daily at 6am PST
Stay ahead of the curve
No breathless headlines. No "everything is changing" filler. Just who moved, what broke, and why it matters.
Free. No spam. Unsubscribe anytime.
The off-peak promotion that aged poorly
Context makes the outage sting. On March 16, Anthropic announced it was doubling five-hour usage limits for all Claude models during off-peak windows, weekdays from 2 p.m. to 8 a.m. Eastern. The promotion covers every subscription tier except Enterprise and runs through March 27.
The message was clear: bring your heaviest tasks. Try Opus 4.6 on something ambitious. Use more.
On March 17, users couldn't use Claude at all.
One person on X put it plainly. "anthropic: free 2x usage for certain hours / claude: down during those hours." Hard to argue.
Two readings are possible. Anthropic has genuine excess capacity during off-peak windows and wants idle GPUs earning their keep. Or the company is trying to spread demand across the day because peak hours can't take the load. If it's the first, well, three outages in 17 days say something about those capacity estimates. If it's the second, the outages suggest the strain exceeds what load-balancing can fix.
Neither reading is reassuring for teams that depend on Claude for production work.
Growing pains or something worse
One outage is an incident. Two suggest a pattern. Three in the same month, for a platform that positions itself as enterprise-ready, start to feel structural.
Anthropic is not short on cash. Two billion dollars in the latest funding round. Four billion from Amazon. The money is there. But capital doesn't automatically produce infrastructure maturity, and throwing hardware at a scaling problem only works if the software layer can distribute load across it. Google burned years building query infrastructure that doesn't flinch under billions of requests. AWS got reliable the hard way, through a decade of painful, iterative fixes that nobody wrote press releases about. Anthropic wants to compress that timeline. It's scaling a consumer chatbot, a developer CLI, a desktop automation tool, and an enterprise API all at once.
That compression is where the anxiety should sit for enterprise customers evaluating Claude. Anthropic has built a strong reputation on safety research, and the technical work backs up the branding. Its model quality, particularly Opus 4.6, draws genuine enthusiasm from developers and researchers. But reliability is a different discipline entirely. It rewards patience, redundancy, and the kind of unsexy operational rigor that doesn't generate headlines or fundraising slides. Three outages in March expose how early the company remains on that curve.
The defensive posture on the status page makes the gap more visible, not less. Saying "only free users are affected" when paid users are posting error screenshots reads less like accurate reporting and more like damage control. Enterprise buyers notice that kind of thing. Every enterprise buyer has seen the pitch deck showing five nines of uptime. The incident reports always come after the contract closes.
Somewhere around 2013, the whale vanished. No clever code fix retired it. Twitter just spent years on boring, unglamorous infrastructure work that nobody wanted to do. New load balancers. Better connection pooling. Redundant data centers that actually fail over when they're supposed to.
Anthropic's outages will stop when the company makes that same kind of investment visible. Until then, every usage promotion is a bet that the servers can deliver what the marketing team promised. Three times in March, they couldn't. And six thousand users sat staring at frozen terminals, waiting for the whale to swim away.
Frequently Asked Questions
Why did Claude go down three times in March?
Anthropic hasn't disclosed root causes for any of the three outages. StatusGator logged over 21,000 incidents in February alone, suggesting persistent infrastructure strain. The company's rapid growth, Opus 4.6's launch, and a usage-doubling promotion likely contributed to increased load.
Were paid Claude subscribers affected by the outage?
Yes. Despite Anthropic's status page claiming only free users were impacted, paid subscribers posted API Error 500 screenshots on X within the hour. Users of Claude Code, Cowork, and the mobile app all reported failures regardless of subscription tier.
What is the fail whale and how does it relate to Claude?
Twitter's fail whale was a cartoon error page shown from 2008 to 2013 when servers buckled under traffic. Claude's repeated outages mirror that pattern: a product growing faster than its infrastructure can support. Twitter took five years of architecture rewrites to fix it.
What was Anthropic's off-peak doubling promotion?
On March 16, Anthropic began doubling five-hour usage limits for all Claude models during off-peak hours (2 p.m. to 8 a.m. Eastern) through March 27. The service went down the next day, making the promotion temporarily irrelevant.
Should enterprises worry about Claude's reliability?
Three outages in 17 days raise legitimate questions. Anthropic has $6 billion in funding but hasn't published post-mortems or disclosed root causes. Enterprise buyers should weigh the gap between status page communications and actual user-reported impact.






