💡 TL;DR - The 30 Seconds Version
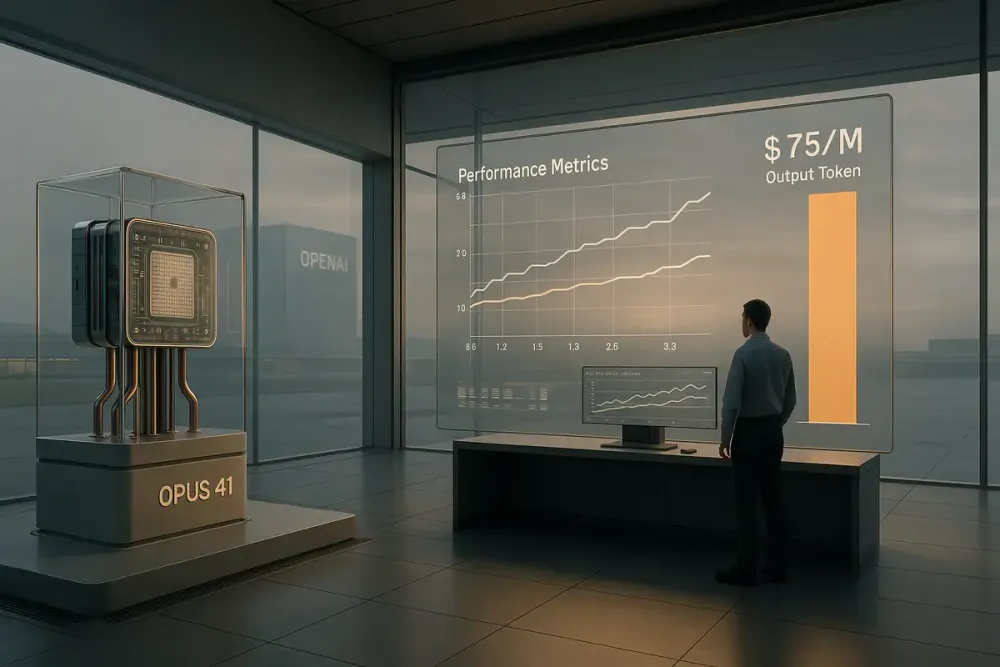
🤖 Anthropic releases Claude Opus 4.1 with 74.5% on SWE-bench Verified—just 2 percentage points better than Opus 4, while some benchmarks actually decreased
💸 At $75 per million output tokens, Claude costs 10x more than OpenAI's GPT-4.1 ($8) and 5-7x more than Google's Gemini ($10-15)
📊 Real improvements are tiny: GPQA Diamond up 1.3%, visual reasoning up 0.6%, while TAU-bench airline scores dropped from 59.6% to 56%
🏢 GitHub, Rakuten, and Block praise multi-file refactoring improvements, with navigation error rates dropping from 20% to "near zero"
⏰ Launch timing isn't subtle—OpenAI's GPT-5 arrives this month while Anthropic seeks $5B funding at a $170B valuation
🎯 The AI pricing bubble faces reality: when 2% better costs 1000% more, markets eventually correct themselves
Anthropic dropped Claude Opus 4.1 today, and here's the thing that jumps out: they're calling it exactly what it is. A point release. Not a revolution, not a breakthrough—just a .1 increment that delivers exactly what you'd expect from that version number.
The company's claiming a market-leading 74.5% on SWE-bench Verified, up from 72.5% in Opus 4. For those keeping score at home, that's a whopping two percentage points. The model tackles real GitHub issues, ensuring patches make failing tests pass without breaking existing ones. It's solid engineering work. But let's talk about what $75 per million output tokens actually buys you these days.
Because that's the elephant in the server room. While Anthropic maintains its premium pricing—$15 per million input tokens, $75 per million output—competitors are practically giving their models away. OpenAI's GPT-4.1 runs $2 for input and $8 for output. Google's Gemini 2.5 Pro? Between $1.25-$2.50 for input, $10-$15 for output. You're paying roughly 10x more for Claude's output. The question isn't whether it's better. It's whether it's that much better.
The Incremental Reality Check
Simon Willison did the homework Anthropic's marketing team hoped nobody would. He extracted the actual benchmark improvements, and they tell a different story than the press release. Graduate-level reasoning on GPQA Diamond? Up from 79.6% to 80.9%. Visual reasoning? A jump from 76.5% to 77.1%. High school math went from 75.5% to 78%.
But wait—it gets better. The TAU-bench airline score actually decreased from 59.6% to 56%. That's right. The new model performs worse on some tasks. When your upgrade goes backward, maybe don't lead with "substantial performance gains."
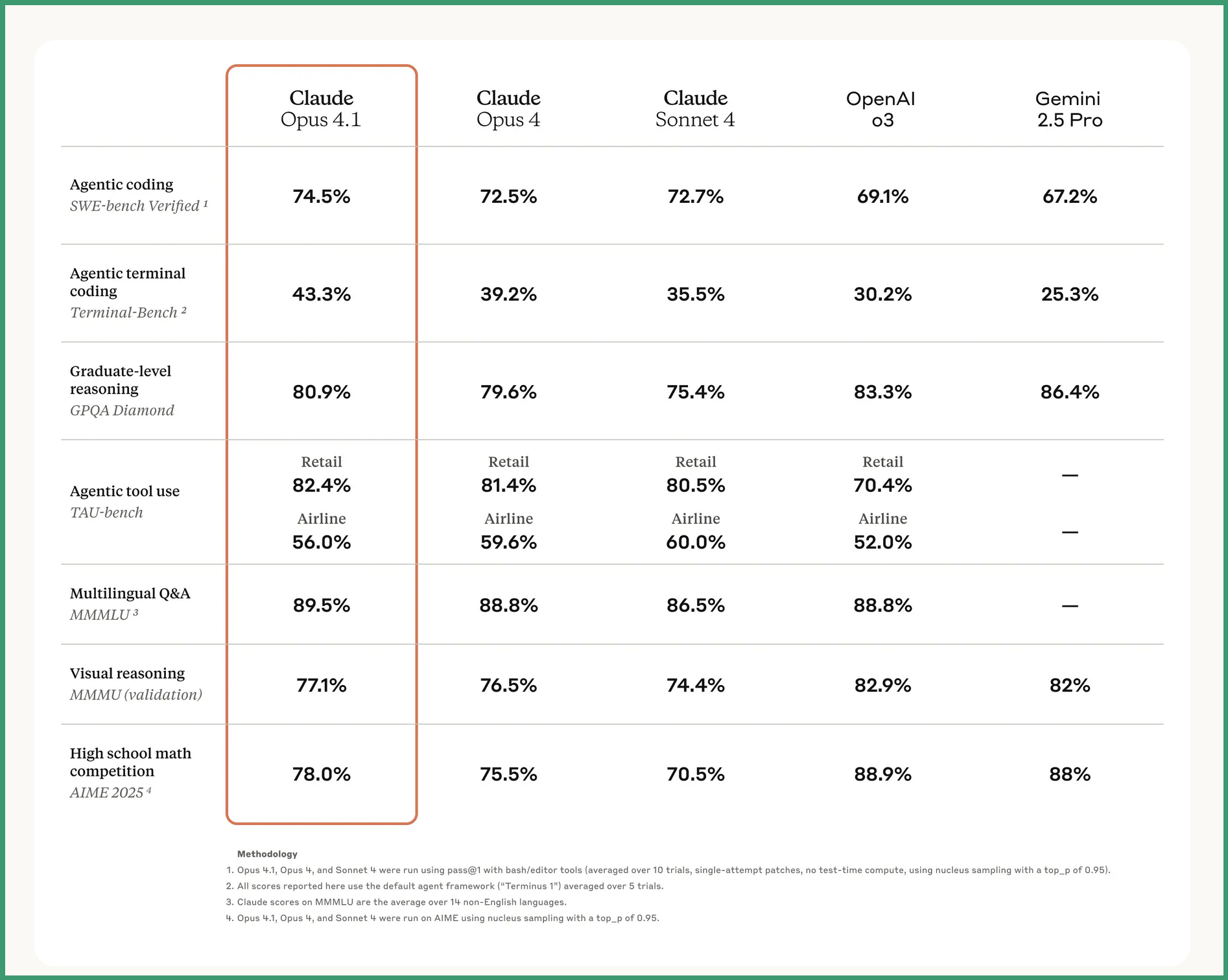
The extended thinking capabilities let Claude chew through 64,000 tokens for complex problems. Anthropic reports 83.3% on GPQA Diamond and 90% on AIME when given sufficient thinking time. Except Simon Willison's data shows AIME at 78%, not 90%. Turns out those numbers depend on whether you're using extended thinking mode. The marketing materials don't exactly clarify this distinction.
Real Companies, Real Results (Sort Of)
GitHub integrated Claude into Copilot and specifically praised "notable performance gains in multi-file code refactoring." That's genuinely useful. Previous models showed navigation error rates around 20%. Claude Opus 4.1 allegedly reduces this to "near zero."
Rakuten Group, the Japanese conglomerate, says the model "excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs." Block calls it "the first model to boost code quality during editing and debugging." Windsurf reports it delivers "a one standard deviation improvement" over Opus 4.
These testimonials sound impressive until you remember companies rarely publicize their AI integrations unless they're happy with them. Nobody's issuing press releases about the models that didn't work out.
The Timing Isn't Coincidental
Bloomberg buried the lede: OpenAI's GPT-5 launch is imminent, possibly this month. Anthropic's Chief Product Officer Mike Krieger played it cool, saying they're "focused on what we have." Sure. Just like how nobody times product launches around competitor releases.
Anthropic's generating about $5 billion in annualized revenue and finalizing a funding round at a $170 billion valuation. Those are serious numbers. But they're also numbers that demand serious growth. Incremental improvements at premium prices might not cut it when OpenAI drops whatever they've been cooking.
The company's shifting toward "more incremental improvements" alongside major releases. Krieger admitted they were "too focused on only shipping the really big upgrades." Translation: We need to ship something while we work on the actual next generation.
Platform Availability and Enterprise Reality
Opus 4.1 launched everywhere simultaneously. Consumer-facing Claude Code provides command-line access with "full codebase awareness and autonomous execution capabilities." Amazon Bedrock offers it in three US regions. Google Cloud Vertex AI provides broader coverage including Europe.
The API implementation supports prompt caching for "up to 90% cost savings" and batch processing for "50% reductions on asynchronous workloads." Those discounts matter when you're charging 10x the competition. Even with maximum optimization, you're still paying more than standard pricing elsewhere.
Enterprise customers aren't stupid. They run cost-benefit analyses. When your benefit is a 2% improvement but your cost is 1000% higher, that math gets challenging. Especially when budgets are tightening and every AI expense needs justification.
Why this matters:
• Anthropic just validated the AI industry's dirty secret: most model improvements are incremental, not revolutionary—yet pricing remains detached from actual performance gains
• The race isn't about capability anymore; it's about value: when a 2% improvement costs 10x more, the market will eventually correct itself, and premium pricing strategies will collapse
Read on, my dear:
Anthropic Press Releas: Claude Opus 4.1
❓ Frequently Asked Questions
Q: What exactly is SWE-bench Verified and why does it matter?
A: SWE-bench Verified tests AI models on 500 real GitHub issues, measuring how many they can fully fix without breaking existing code. Models must make failing tests pass in containerized repos. Claude's 74.5% score means it successfully fixes about 372 out of 500 real coding problems. It's the closest benchmark we have to actual developer work.
Q: Why do the benchmark numbers vary between sources?
A: Anthropic reports different scores depending on whether "extended thinking" mode is enabled, which allows up to 64,000 tokens of processing. AIME scores jump from 78% to 90% with extended thinking. GPQA Diamond goes from 80.9% to 83.3%. The marketing materials don't always clarify which mode was used for each score.
Q: How much can prompt caching and batch processing actually save?
A: Prompt caching cuts costs up to 90%, bringing Claude's $75/million output tokens down to $7.50. Batch processing saves another 50%, potentially reaching $3.75. But even with maximum optimization, you're still paying about half of competitors' standard rates. Without these discounts, a million-token conversation costs $75 versus $8-15 elsewhere.
Q: What does "multi-file code refactoring" improvement actually mean?
A: When changing code that affects multiple files, models often break dependencies or miss related updates. Previous models had 20% navigation error rates—failing to find or update all affected files. Claude 4.1 reduces this to "near zero," meaning it successfully tracks and updates code changes across entire codebases without introducing bugs.
Q: How does Anthropic's $5 billion revenue compare to OpenAI?
A: Anthropic generates about $5 billion annualized revenue at a $170 billion valuation. OpenAI reportedly makes $3.7-4 billion annually but at a lower $157 billion valuation. Despite similar revenues, Anthropic charges 10x more per token, suggesting they have far fewer API calls but higher-value enterprise customers.
Q: What is Claude Code and how does it differ from the API?
A: Claude Code is a command-line tool that gives Claude "full codebase awareness and autonomous execution capabilities." Unlike the API which processes individual requests, Claude Code can navigate entire projects, run commands, and make changes across files automatically. It's designed for developers who want Claude to act as an autonomous coding assistant.
Q: Which benchmarks actually got worse in Opus 4.1?
A: TAU-bench airline performance dropped from 59.6% to 56%—a 3.6 percentage point decrease. This benchmark tests AI agents' ability to handle airline booking scenarios with multiple tools. The decline suggests that improvements in coding and reasoning sometimes come at the cost of performance in other specialized tasks.
Q: When is GPT-5 actually launching and how might it compare?
A: OpenAI executives suggest GPT-5 arrives this month (August 2025), though it's been delayed multiple times. No benchmarks exist yet, but OpenAI's current GPT-4.1 already costs 90% less than Claude while scoring similarly on most tests. If GPT-5 maintains that pricing with significant capability jumps, Anthropic's premium model faces serious pressure.



Marcus Schuler
Tech translator with German roots who fled to Silicon Valley chaos. Decodes startup noise from San Francisco. Launched implicator.ai to slice through AI's daily madness—crisp, clear, with Teutonic precision and sarcasm. E-Mail: [email protected]


