💡 TL;DR - The 30 Seconds Version
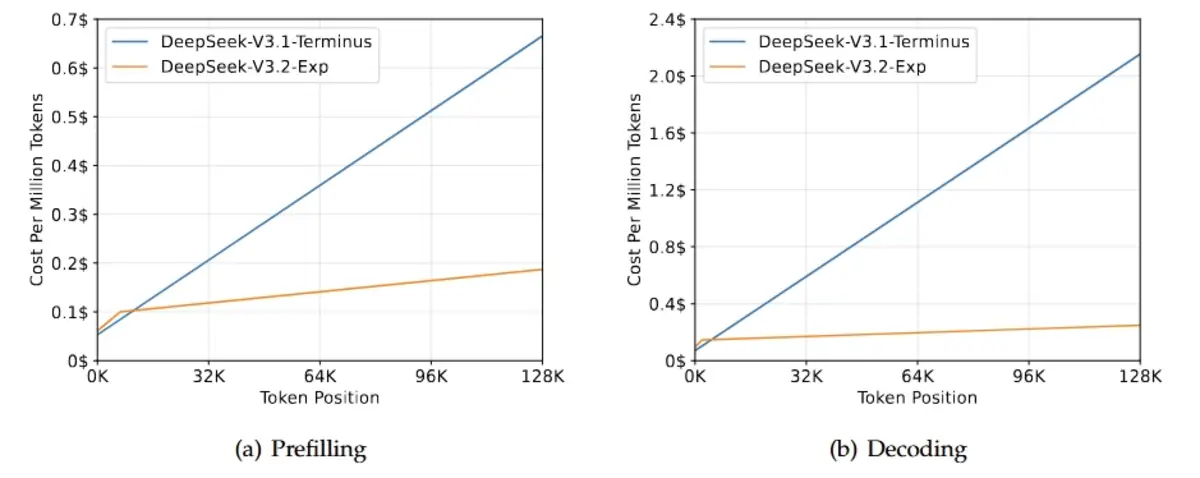
💰 DeepSeek released V3.2-Exp Monday with sparse attention that processes 128,000-token contexts for $0.25—down from $2.20 with dense attention—while cutting API prices by more than 50%.
⚡ The sparse attention mechanism uses a "lightning indexer" to selectively process relevant tokens, reducing computational complexity from O(L²) to O(L × k) while maintaining output quality matching V3.1-Terminus.
🔬 DeepSeek trained the model with 1 trillion additional tokens, built five specialized models through reinforcement learning, then distilled them using FP8 quantization and open-source kernels.
🎯 Chinese rivals like Alibaba's Qwen face immediate pricing pressure in the domestic market, while OpenAI must justify premium pricing against capabilities that shrink with each DeepSeek release.
🇨🇳 Huawei announced same-day chip support, deepening integration between Chinese AI developers and domestic semiconductor makers as U.S. export controls restrict Nvidia access.
🔄 DeepSeek calls V3.2-Exp an "intermediate step" toward next-generation architecture, using the release to validate techniques before the main flagship model that could repeat R1's market impact.
Sparse attention technique slashes long-context pricing. Chinese startup's "intermediate" release intensifies AI price war.
DeepSeek released an experimental AI model Monday that processes 128,000-token contexts for $0.25—down from $2.20 using dense attention. The Hangzhou-based startup simultaneously cut API prices by more than 50%, weaponizing a technical innovation called DeepSeek Sparse Attention to pressure both Chinese rivals and OpenAI on cost.
The V3.2-Exp model isn't DeepSeek's next flagship—the company explicitly calls it "an intermediate step toward our next-generation architecture." But the release demonstrates how architectural improvements translate directly into pricing power. The sparse attention mechanism reduces computational complexity for long sequences while maintaining output quality virtually identical to the V3.1-Terminus model it builds upon.
The sparse attention arithmetic
DeepSeek Sparse Attention achieves what the company calls "fine-grained sparse attention"—selectively processing only relevant portions of long text sequences rather than computing full attention across every token. The mechanism uses a "lightning indexer" with top-k attention, dropping inference costs from O(L²) to O(L × k) where k << L.
Technical implementation matters here. DeepSeek trained V3.2-Exp with 1 trillion additional tokens beyond V3.1-Terminus, then built five specialized models through reinforcement learning before distilling them into the final checkpoint. The approach uses GRPO (Group Relative Policy Optimization) with reward functions penalizing length verbosity, enforcing language consistency, and applying rubric-based quality checks.
The company released open-source kernels through three repositories—TileLang for research-focused readability, DeepGEMM for high-performance indexer logit operations, and FlashMLA for sparse attention. FP8 quantization further reduces memory requirements and accelerates computation, though DeepSeek indicates it's working toward BF16 support for higher training precision.
Performance remains comparable to V3.1-Terminus across public benchmarks. MMLU-Pro holds at 85.0, Codeforces improves slightly from 2046 to 2121, SWE-bench Multilingual stays near 58%. The architectural shift trades marginal benchmark movements for substantial cost reduction—a calculated exchange when the goal is market penetration through pricing.
The competitive squeeze begins
DeepSeek's pricing cut arrives six months after its R1 model shocked Silicon Valley with capabilities achieved at a fraction of typical training costs. The pattern now extends to inference: deliver comparable performance at dramatically lower cost, forcing competitors to match prices or justify premium positioning.
For Chinese rivals, the pressure is immediate. Alibaba's Qwen competes directly in the domestic market where pricing sensitivity runs high. ByteDance's models face similar dynamics. DeepSeek's strategy resembles classic loss-leader economics—use technical efficiency to establish cost leadership, then leverage that position to capture market share before competitors can restructure their own architectures.
For OpenAI, the calculation is different but the pressure real. GPT-4 pricing remains substantially higher than DeepSeek's, justified by capability advantages that shrink with each DeepSeek release. The sparse attention technique isn't proprietary—the kernels are open-source—but integrating architectural changes into production systems takes time. OpenAI must either accept margin compression or defend premium pricing through capabilities that justify 5-10x cost differences.
The Chinese ecosystem play
Huawei Technologies announced same-day support for DeepSeek's V3.2-Exp on its AI chips. The timing reflects deepening integration between Chinese AI developers and domestic semiconductor makers as U.S. export controls restrict access to Nvidia's most advanced hardware.
DeepSeek's focus on FP8 quantization aligns with capabilities of Chinese-manufactured chips. While Nvidia's H100 and H200 dominate global AI infrastructure, Huawei's Ascend processors and other domestic alternatives can run FP8 workloads effectively. The architectural optimization isn't just about cost—it's about reducing dependence on restricted hardware.
This creates reinforcing dynamics. DeepSeek develops models optimized for available chips; Chinese chipmakers optimize for DeepSeek's architectures; developers build on platforms that work with domestic hardware. The ecosystem doesn't yet match Nvidia-CUDA-OpenAI integration, but the gap narrows with each release.
The "intermediate step" positioning
DeepSeek's explicit framing of V3.2-Exp as experimental and intermediate serves multiple purposes. It manages expectations—this isn't the R1 sequel that will shock markets again. It signals ongoing research—sparse attention represents one path among several being explored. And it builds anticipation—the "next-generation architecture" remains forthcoming.
The benchmark results support cautious positioning. Performance matches but doesn't exceed V3.1-Terminus. Humanity's Last Exam drops from 21.7 to 19.8, HMMT 2025 falls from 86.1 to 83.6—small enough to attribute to noise, large enough to avoid claiming breakthrough status. DeepSeek is validating techniques, not declaring victory.
But validation at dramatically lower cost creates its own competitive pressure. If sparse attention works at this scale, expect rapid adoption across the industry. TensorFlow and PyTorch implementations will follow. The efficiency gains become table stakes rather than differentiation.
Why this matters:
• Architectural innovation now translates directly to pricing pressure. The sparse attention technique isn't magic—it's engineering that reduces computational requirements by selectively processing relevant tokens. But that engineering enables 10x cost reductions that force industry-wide responses.
• The Chinese AI ecosystem is vertically integrating around domestic constraints. DeepSeek optimizes for FP8 and Chinese chips; Huawei ships day-zero support; open-source kernels enable rapid adoption. Export controls accelerate rather than prevent technical development—they just redirect it toward self-sufficient architectures.
❓ Frequently Asked Questions
Q: What exactly is sparse attention and how does it cut costs?
A: Traditional dense attention processes every token against every other token in a sequence—computationally expensive at O(L²) complexity. Sparse attention uses a "lightning indexer" to identify and process only the most relevant tokens through top-k selection, reducing complexity to O(L × k) where k is much smaller than L. For a 128,000-token context, this drops costs from $2.20 to $0.25.
Q: Why is DeepSeek calling V3.2 "intermediate" instead of their next flagship?
A: DeepSeek is using V3.2-Exp to validate sparse attention techniques before committing to a full architectural overhaul. The company trained it with configurations deliberately aligned to V3.1-Terminus to isolate the impact of sparse attention alone. Benchmarks show performance parity, not breakthrough gains—this is technical validation, not a market-shocking release like R1 was in January.
Q: What's the difference between FP8 and BF16 that DeepSeek mentions?
A: FP8 (Floating Point 8) uses 8 bits to store numbers, saving memory and speeding calculations but with lower precision. BF16 (Brain Floating Point 16) uses 16 bits, offering better accuracy for training AI models. DeepSeek's V3.2 supports FP8 now—good for inference on Chinese chips with limited memory—while working toward BF16 support for higher-quality training.
Q: Since the kernels are open-source, can competitors just copy this approach?
A: The code is available through TileLang, DeepGEMM, and FlashMLA repositories, but integrating sparse attention into production systems takes months. Companies must retrain models, rebuild inference pipelines, and validate output quality at scale. DeepSeek gets a 6-12 month head start on pricing and can iterate faster. OpenAI and others will adopt similar techniques, but DeepSeek moves first.
Q: How do U.S. export controls connect to DeepSeek's technical choices?
A: U.S. restrictions limit Chinese access to Nvidia's H100 and H200 chips. DeepSeek optimizes for what's available—Huawei's Ascend processors and other domestic alternatives that handle FP8 well but lack the memory and compute of restricted chips. The sparse attention technique compensates for hardware limitations by reducing computational requirements. Export controls don't stop development; they redirect it toward self-sufficient architectures.