

Researchers from Renmin University and Huawei have discovered that GUI agents—AI systems that navigate user interfaces—perform better when they don't overthink. Their new model, GUI-G1, achieves state-of-the-art performance by abandoning the lengthy reasoning chains that recent models have adopted from language AI systems.
The finding challenges a core assumption in the field. While OpenAI's o1 and DeepSeek's R1 models demonstrate that extended reasoning improves math and coding tasks, the same approach backfires for visual interface navigation. GUI agents predominantly utilize text-based representations such as HTML or accessibility trees, which, despite their utility, often introduce noise, incompleteness, and increased computational overhead.
"Grounding is more like instant visual recognition than deliberative problem-solving," the researchers explain. When an AI needs to find a button or menu item on screen, forcing it to "think out loud" actually degrades accuracy—especially when the target is text rather than an icon.
The team identified three critical flaws in current training approaches:
Visual tasks don't need verbal reasoning
Models trained to generate explanations before answering performed worse as their reasoning grew longer. The researchers found that grounding performance relies more on processing image tokens than generating text. A model trying to locate "the network settings button" doesn't benefit from first describing what networks are or why someone might want to adjust settings.
Reward systems create size problems
Current training rewards lead to what researchers call "reward hacking." When optimized for accuracy alone, models learned to predict tiny bounding boxes. When optimized for overlap with ground truth, they produced oversized boxes. Neither approach reliably identified the actual UI elements users need.
Training favors easy examples
The standard GRPO (Group Relative Policy Optimization) algorithm has built-in biases. It encourages unnecessarily long incorrect responses while focusing training on simple cases, preventing models from mastering difficult scenarios like finding small icons in cluttered interfaces.
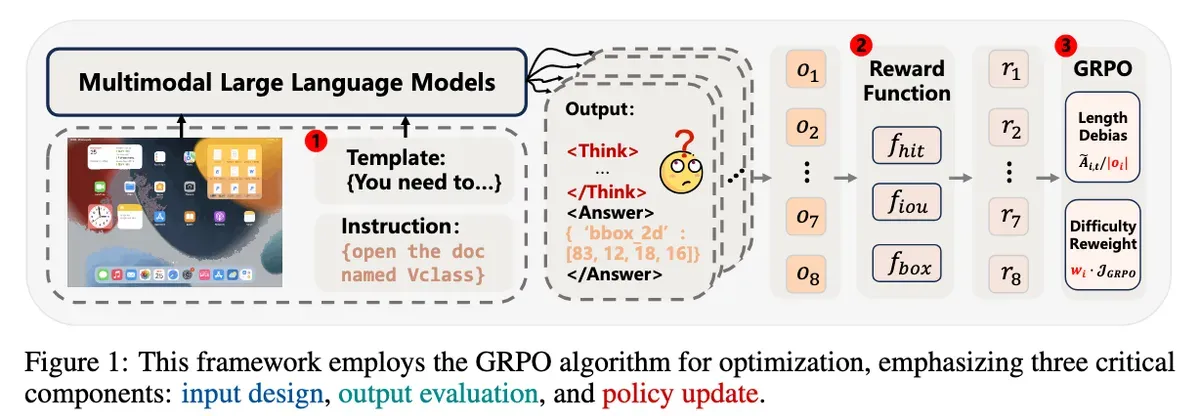
The researchers developed targeted solutions for each issue. They introduced a "Fast Thinking Template" that skips reasoning during training. They added box-size constraints to prevent gaming the reward system. They modified the training algorithm to weight harder examples more heavily and removed length normalization that was encouraging verbose failures.
Their GUI-G1-3B model, despite using only 17,000 training examples, outperforms larger models trained on millions of samples. It achieves 90.3% accuracy on ScreenSpot and 37.1% on the more challenging ScreenSpot-Pro benchmark—surpassing the previous best model, InfiGUI-R1, while generating three times fewer tokens.
Join 10,000 readers who get tomorrow's tech news today. No fluff, just the stories Silicon Valley doesn't want you to see.
Most existing GUI agents interact with the environment through extracted structured data, which can be notably lengthy (e.g., HTML) and occasionally inaccessible (e.g., on desktops). This makes purely visual approaches increasingly important. UGround substantially outperforms existing visual grounding models for GUI agents, by up to 20% absolute, showing the field is rapidly advancing.
The work reveals a fundamental insight about AI capabilities: different tasks require different cognitive approaches. Just as humans instantly recognize familiar visual patterns without conscious reasoning, GUI agents perform better when they act on immediate visual understanding rather than verbose analysis.
Why this matters:
- Training AI systems requires matching methods to tasks—copying successful approaches from language models can harm performance in visual domains
- Efficient GUI navigation could enable more accessible computing interfaces and better automation tools, using fewer computational resources than current approaches
Read on, my dear:
GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents










